
压测过程中,程序内存溢出并重启,原因排查
首先排查进程运行情况,因为进程所在 Pod 已经重启
通过 K8s Pod 监控可以看到服务在 12:40 后,CPU 飙升, CPU 飙升往往是持续 GC 导致的
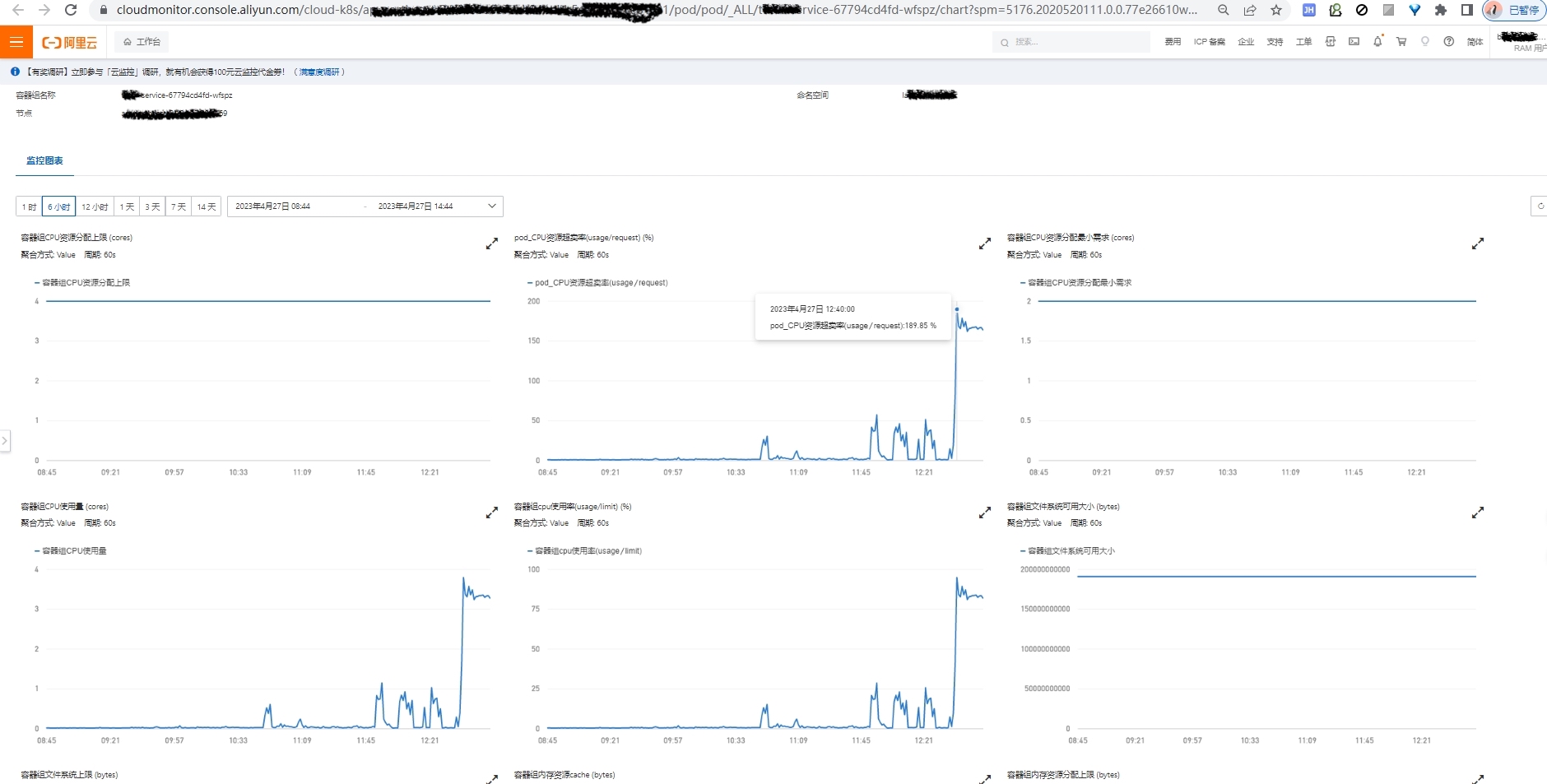
下一步排查数据库情况,虽然数据库 CPU 存在 100% 情况,但是只是一瞬间,没有持续,说明瓶颈是在应用程序,压力没有持续传导到数据库,应用程序本身已经崩溃了
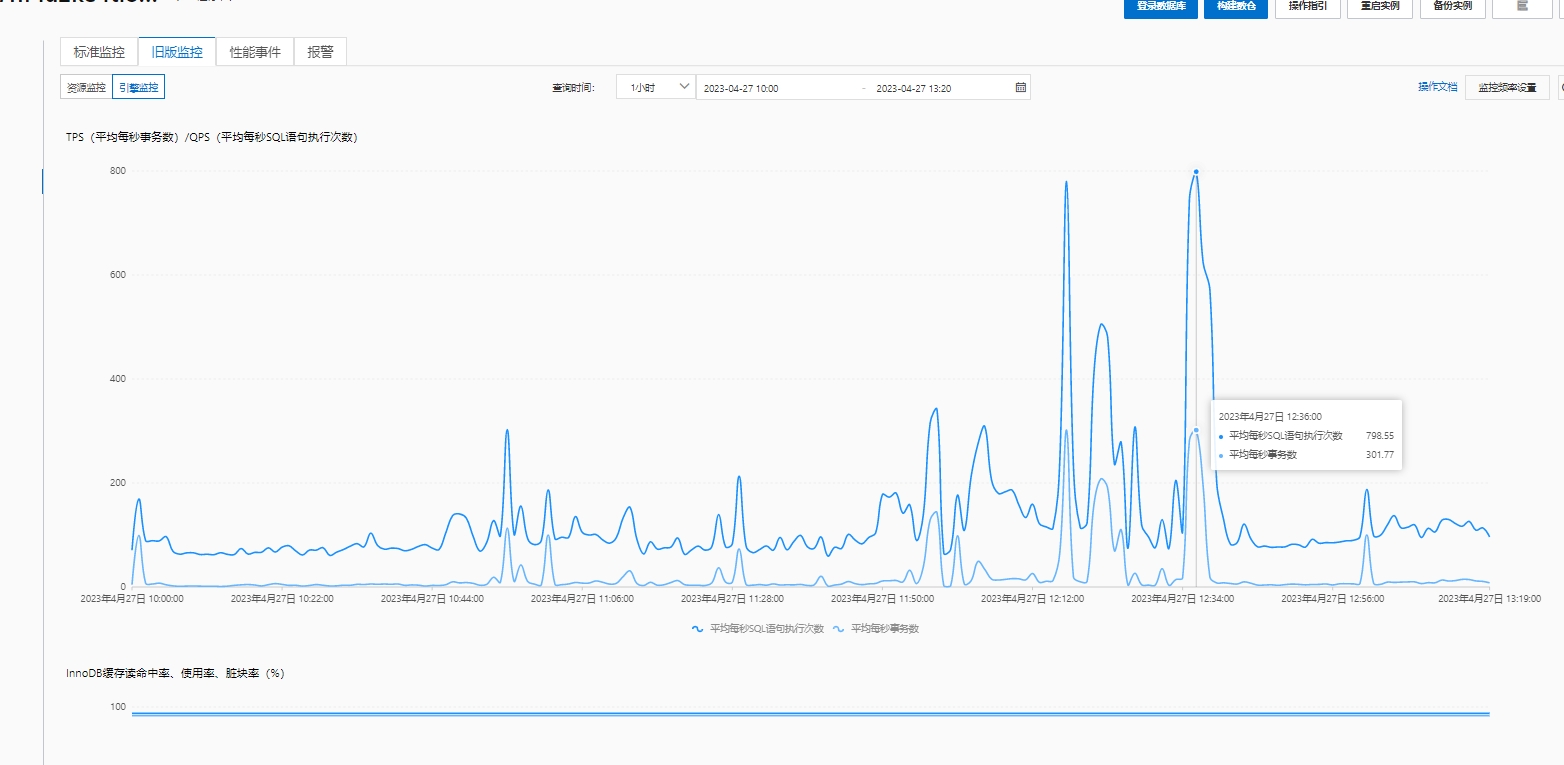
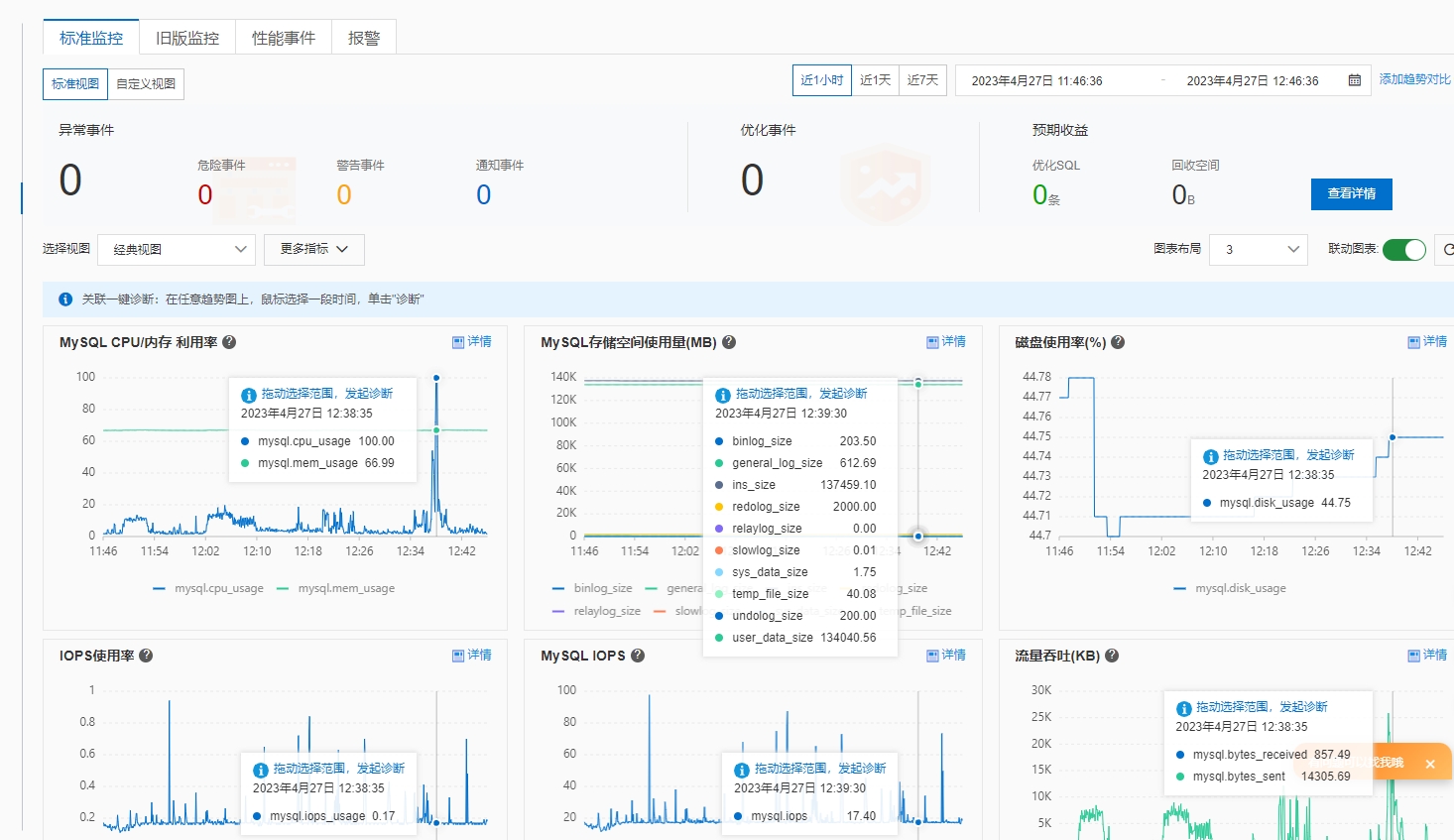 细看数据库引擎情况,分析 CPU 100% 原因,发现没有慢 SQL 等其他异常, 更新和扫描行数也正常,通过 TPS 分析发现 SQL 执行次数飙升
细看数据库引擎情况,分析 CPU 100% 原因,发现没有慢 SQL 等其他异常, 更新和扫描行数也正常,通过 TPS 分析发现 SQL 执行次数飙升
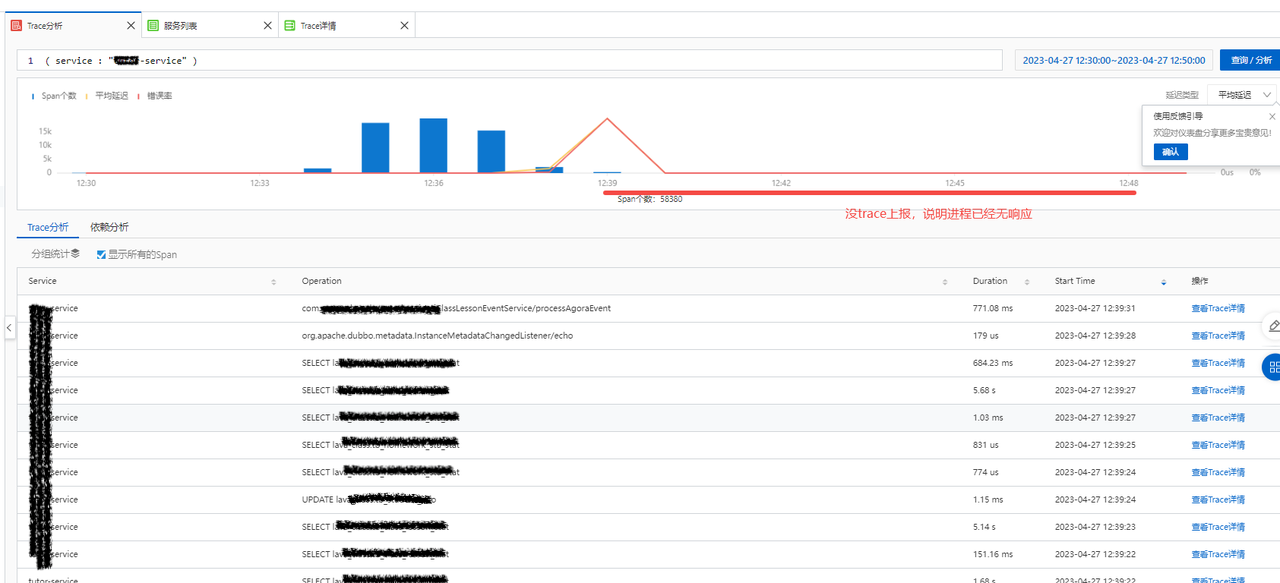
下一步是排查应用程序本身的 Trace 情况,通过 Trace 只能分析到程序运行的表象,即:请求量暴增后,进程无响应,日志/Trace 等无法上报,并且被 K8s 驱逐
因为我们的 gc 日志和应用日志都会实时采集到阿里云日志平台,所以直接查询服务 gc 日志进行分析,显示此时存在非常高频的 GC,导致CPU持续100%
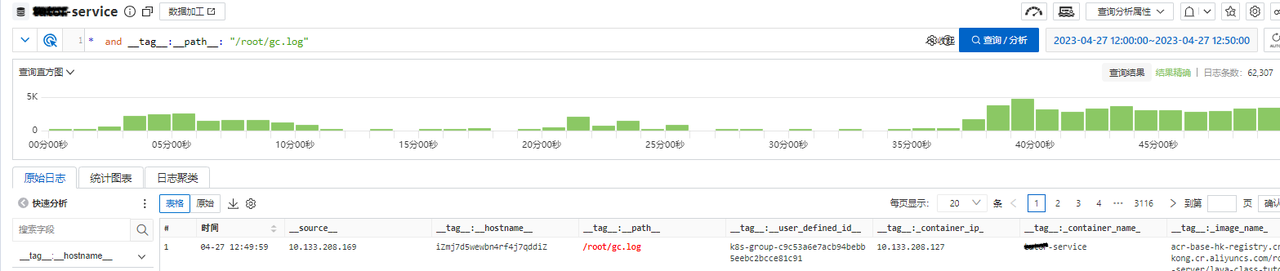
把 GC 日志通过 gceasy 进行分析,提示严重的 GC 问题,但是,此时我们只是明确了程序 CPU 高的原因,还不能排查出为什么程序 GC 由什么原因引起
Brilliant GC graphs, metrics and KPIs.pdf
截取故障前后的应用日志,可看到 GC 频繁,和接口请求情况,其中 Total 3k 的日志嫌疑最大

排查到此,已经锁定了嫌疑的业务逻辑,但是还是没办法实锤,可能会导致优化方向错误
我们 JVM 配置了内存溢出时 dump 堆栈信息,并且外挂目录 Volumes 可用,从中找到了故障时的 dump 文件, 下载 dump 文件进行分析
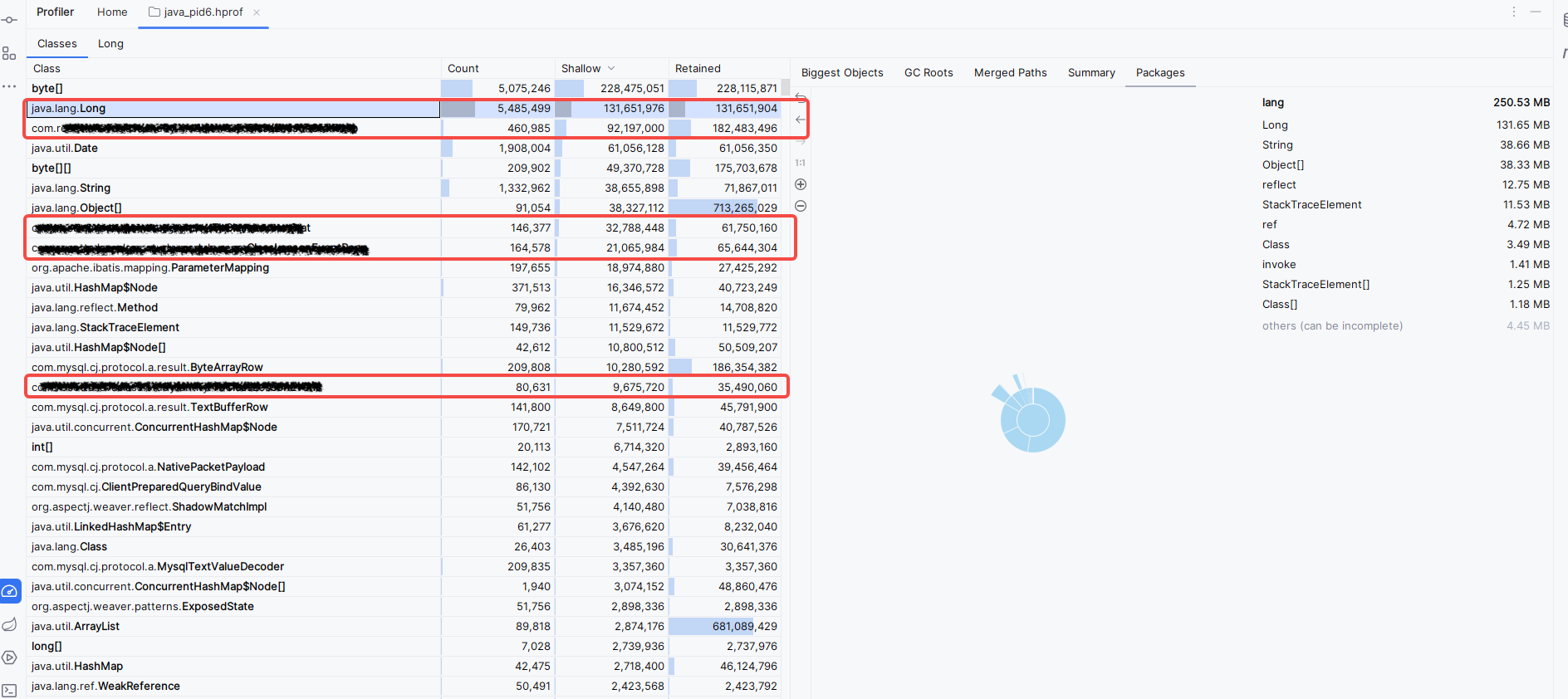
锁定了明确的内存溢出对象
主因有两个,两个接口没实现缓存和其他优化,在大并发情况下占用内存过多,通过调整实现和层层缓存的方式解决
2023-04-27 12:38:56,780 INFO [4d7081320642116bc8a08b4ebeec8ea6 9b0b4f9a7a2ee351 01] [rtri-protocol-12390-thread-188] c.r.h.d.f.ProviderTraceFilter:48 - [] enter provide,ApiClassLessonStatService.listByClassLessonIdsAndUids|called:10.133.208.76:53836|params:[[8136,8137,8358,8359,8382],[2013000081453,2013000085861,2013000085863,800个元素...]]
2023-04-27 12:39:02,177 INFO [665479416c6231df15caa14e73b19296 ab8926e54d10690f 01] [rtri-protocol-12390-thread-288] c.r.h.d.f.ProviderTraceFilter:48 - [] enter provide,ApiClassLessonEventService.list|called:10.133.208.54:55352|params:[8383,null,["stu_connect"]]