
系统架构的介绍
我会按照信令的系统架构上的分布或子系统的层级关系来展开
首先,信令是一个通用的消息系统,主要是为了解决实时场景下信令的低延迟和高并发问题
我们目前的业务形态是不同大区数据隔离,所以我们是分国家大区部署的,没做跨国数据传输
每个大区都有两个子系统分别是:h3p 系统,他代表了用户侧的接入,还有频道系统,他代表了频道房间管理
h3p 系统
首先是 h3p,他有两个服务,ap 和 h3proxy
ap 负责用户的接入点就近选择,也用来实现灰度和灾备切换
h3proxy 负责用户长链接保持和用户房间关系维护,并基于序列号的补偿机制来保证消息不重不丢,h3proxy 基于serverless 部署,同一个房间可以分布在 N 多个 h3proxy 节点中,具有非常大的扩展性
这些的服务都是无状态分布式的,没有一个单点或者中心式的情况,因此可以保证高可用,并且性能方面可以支持高吞吐量和低延迟,只支持基本核心的功能,剩下的都要放在其它子系统
对外提供以下核心功能: 单播消息、频道广播消息,一般消息和可靠消息,进出频道以及事件
他有几个优势特性:
- 消息可靠,不丢失,不乱序
- 消息低延时节点
- 可水平扩展
- 万人同频道
以频道广播消息为例,和大家分享一下消息下发的流程。
首先用户登录时,会先访问 ap 服务,携带业务信息,如事先分配好的频道号和 uid
ap 知道所有的 h3proxy 地址,会根据当前的客户端的地理分布,包括节点的负载/灰度情况来给用户返回一组地址,我们经常在这里控制用户路由到不同的 h3proxy 部署,如 k8s 集群或者 serverless 集群,用户在拿到地址之后,可以连接 h3proxy 节点
h3proxy 和用户保持长链接后,会在实例内维护用户和频道的关系,维护用户的最近可靠消息列表
当有频道广播消息下行时,消息会先进入频道消息发送队列,然后根据用户频道关系找出所有的用户列表,如果消息是不可丢失的可靠消息,则维护用户级的可靠消息列表
当用户接收消息的过程中,根据消息序号发现存在消息丢失时,则会主动过来服务端拉取补偿,从而保证不丢失
可拓展设计是我们基于 serverless 部署,每个部署我们设置了链接上限,当函数超过连接上限时会主动拉起新实例,从而能做到数万人同频道
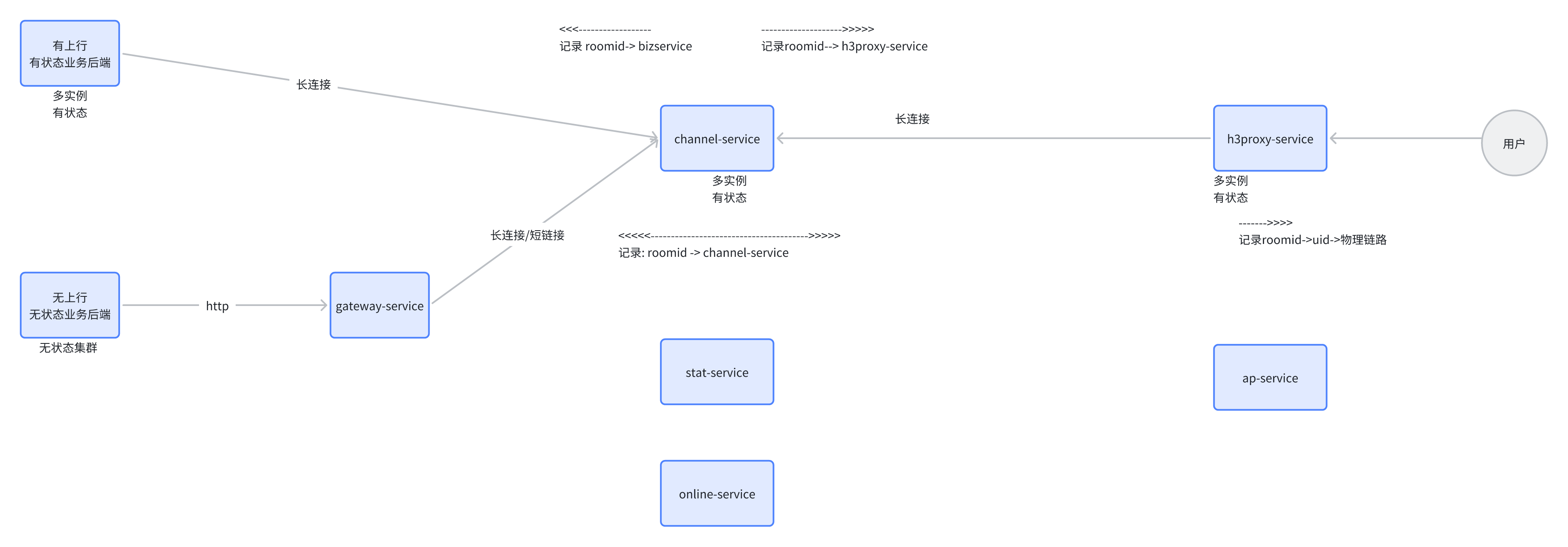
频道系统
频道系统有四个服务: channel/gateway/online 和 stat
channel 第一个功能是频道流量转发,第二个功能是负责频道状态属性和用户属性的维护,并且产生对应的同步事件下发到各端
gateway 负责 channel 实例的发现和路由维护,对外提供 http 接口
online 负责频道在线用户维护,并且产生事件
stat 则是统计相关,并且负责事件的持久化
这里除了 channel 是有状态服务,其他都是可弹性拓展
整体架构
架构的难点
架构的难点: 流量路由如何设计
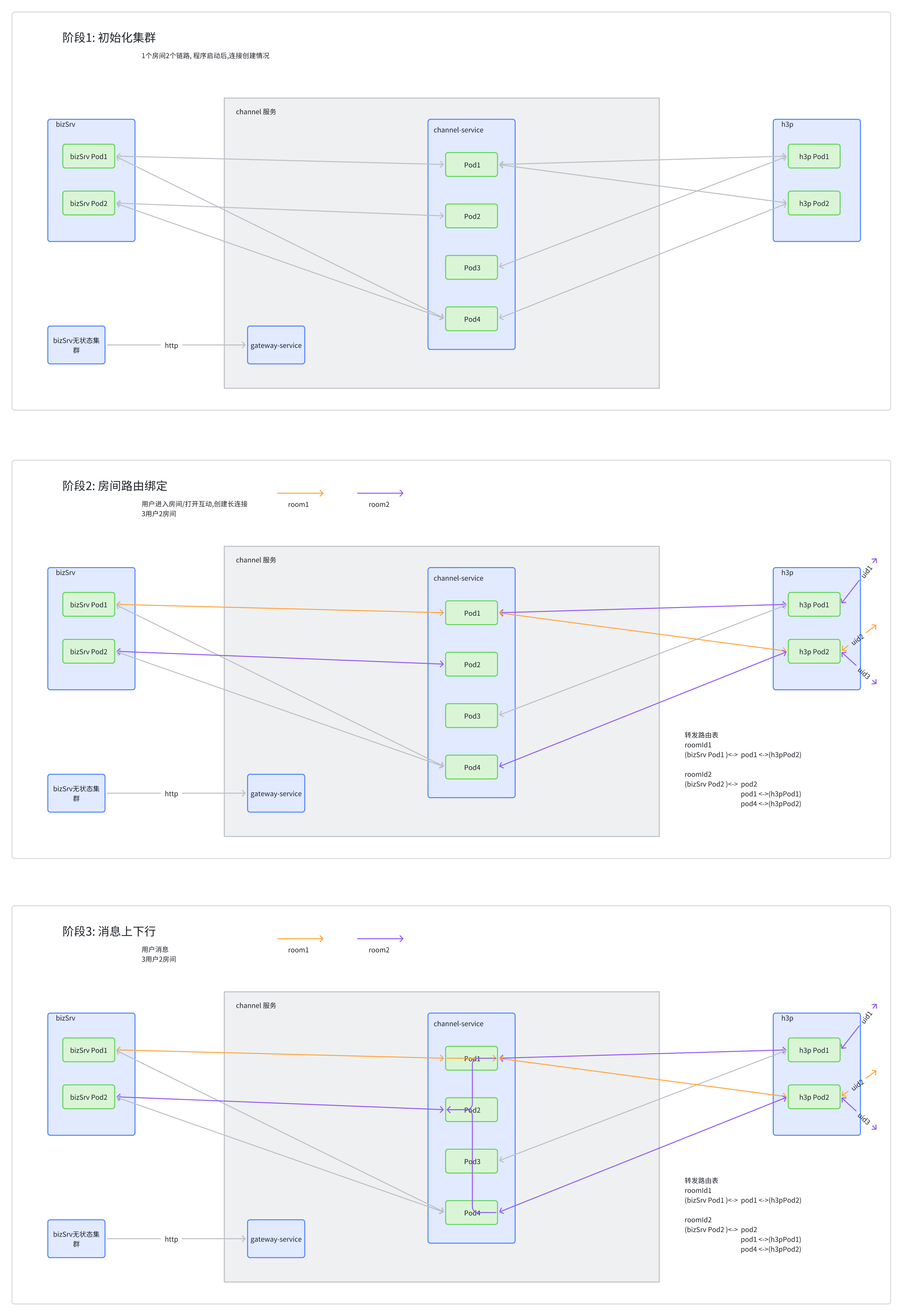
信令系统运行时,channel 和 h3proxy 都是多实例部署,当一个频道消息下发时,究竟是走哪一个channel,去到哪个 h3proxy 呢,我们设计了两个方案:
静态路由
- channel 每一个实例都拥有自己的 Headless Service
- 频道一定会根据算法固定到某一个 channel 实例上
- h3proxy 和 bizSrv 程序启动时,会预热对所有 channel 实例的长连接
- 当有 用户进入频道时,h3proxy 和 bizSrv 会把根据算法把本实例注册到某一个 channel 的路由表上
- channel 在做消息的上下行投递时,就会根据路由表进行投递
- 优点是实现简单,缺点是 channel 伸缩时有配置工作量,房间算法需要检查
集群路由
- 所有 channel 实例组成集群,对外提供一个 Headless Service
- channel 集群节点之间互相感知,并且共同维护一个路由表
- h3proxy 和 bizsrv 程序启动时,预热的长连接会随机到 channel 的某几个实例上,分散压力
- 当有 用户进入频道时,h3proxy 和 bizSrv 直接把本实例注册到某一个 channel 实例上,会同步到路由表
- channel 在做消息的上下行投递时,就会根据路由表进行投递,会在 channel 节点之间进行转发
- 优点是简化接入端的步骤,提高集群的性能和拓展能力,缺点是 channel 实现复杂
集群版转发流量路由
房间管理逻辑路由
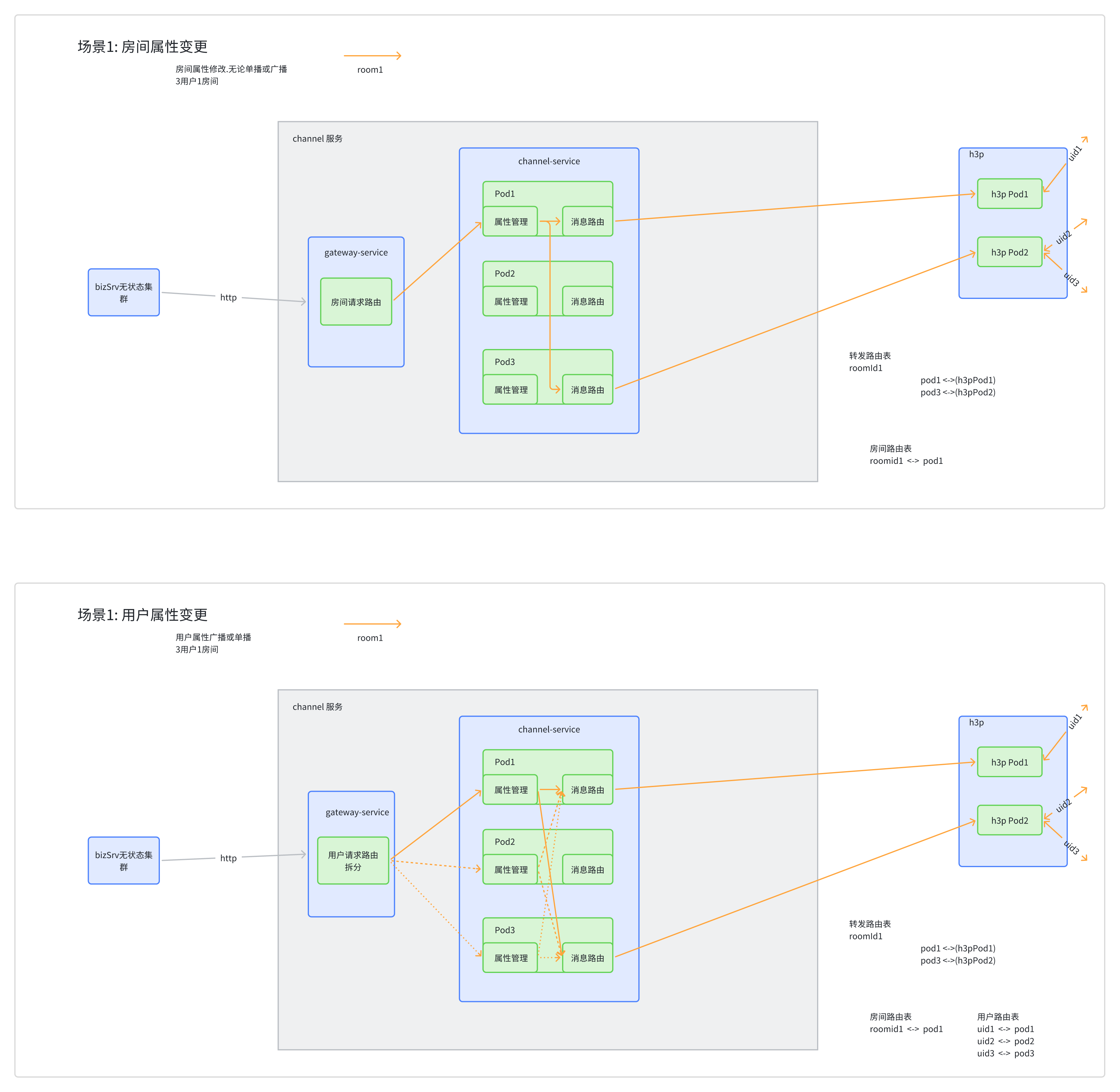
架构的难点: 直播间属性抽象,并且保证保证多端状态一致
直播间会有不同的配置/状态/挂件/互动应用,如何保证在老师端切换状态,发起互动时,所有的端都能实时准确的同步这些变更,有以下的情况
- 如何保证准确的同步这些变更
- 直播间功能根据重要程度进行分级,如何直播间核心状态能够正常
- 某一些互动消息允许丢失,某一些互动状态不允许出错
- 某一些互动只需要通知到老师
我们的方案是:
- channel 维护房间属性快照,每一次变更时比较比较出差异,形成属性变更消息同步给各个端,用户端进入房间时,全量同步房间属性快照,课中变更,采用增量消息下发
- 房间属性进行分级,分为核心属性和互动属性,核心属性消息每次都全量更新,保证只要接收到最后的消息就能做到房间最终状态
- 和 h3proxy 设计联动,允许丢失属性变更使用一般消息,不允许出错互动采用可靠消息
- 和 h3proxy 设计联动,使用频道广播和频道单播
直播间属性结构
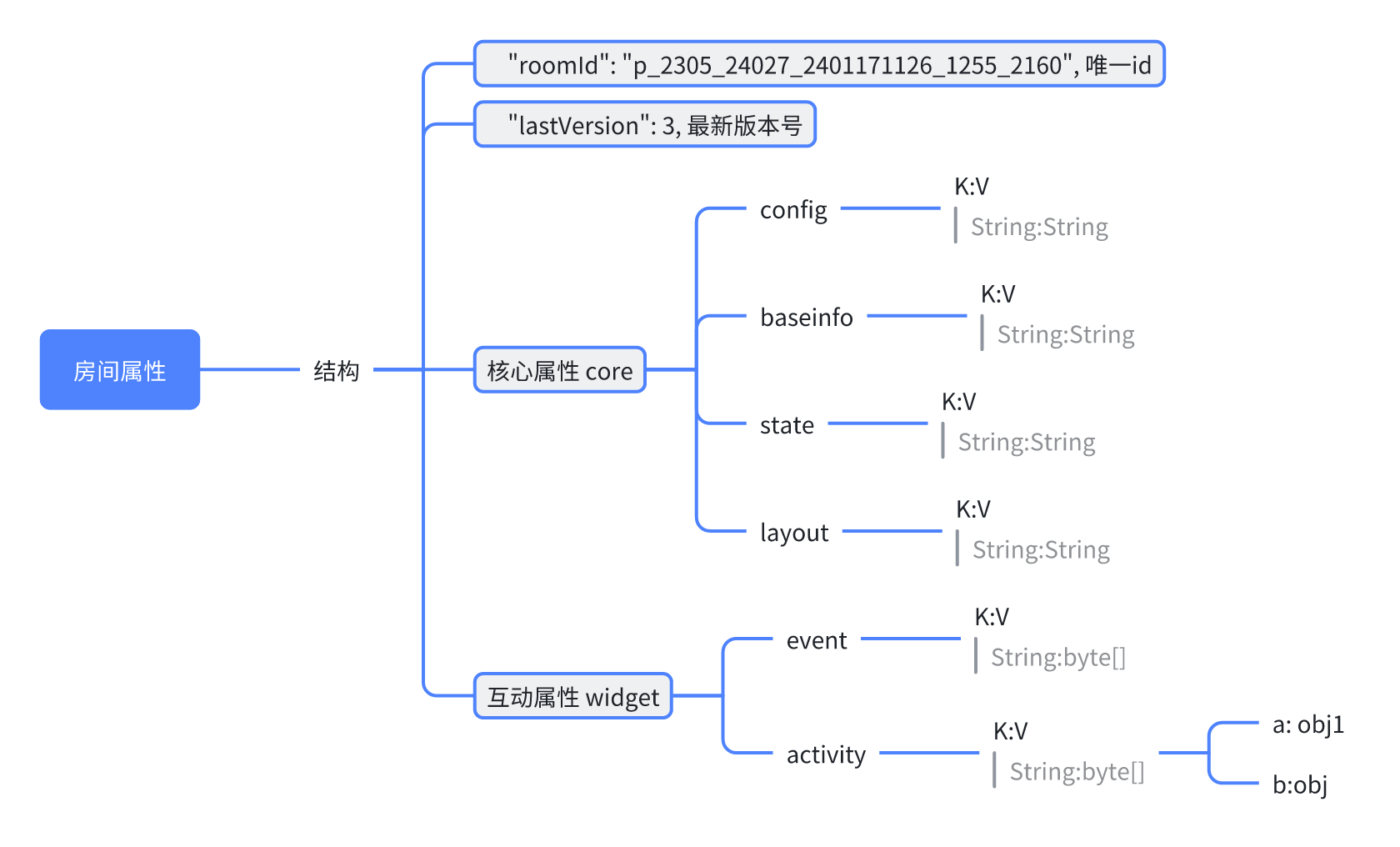
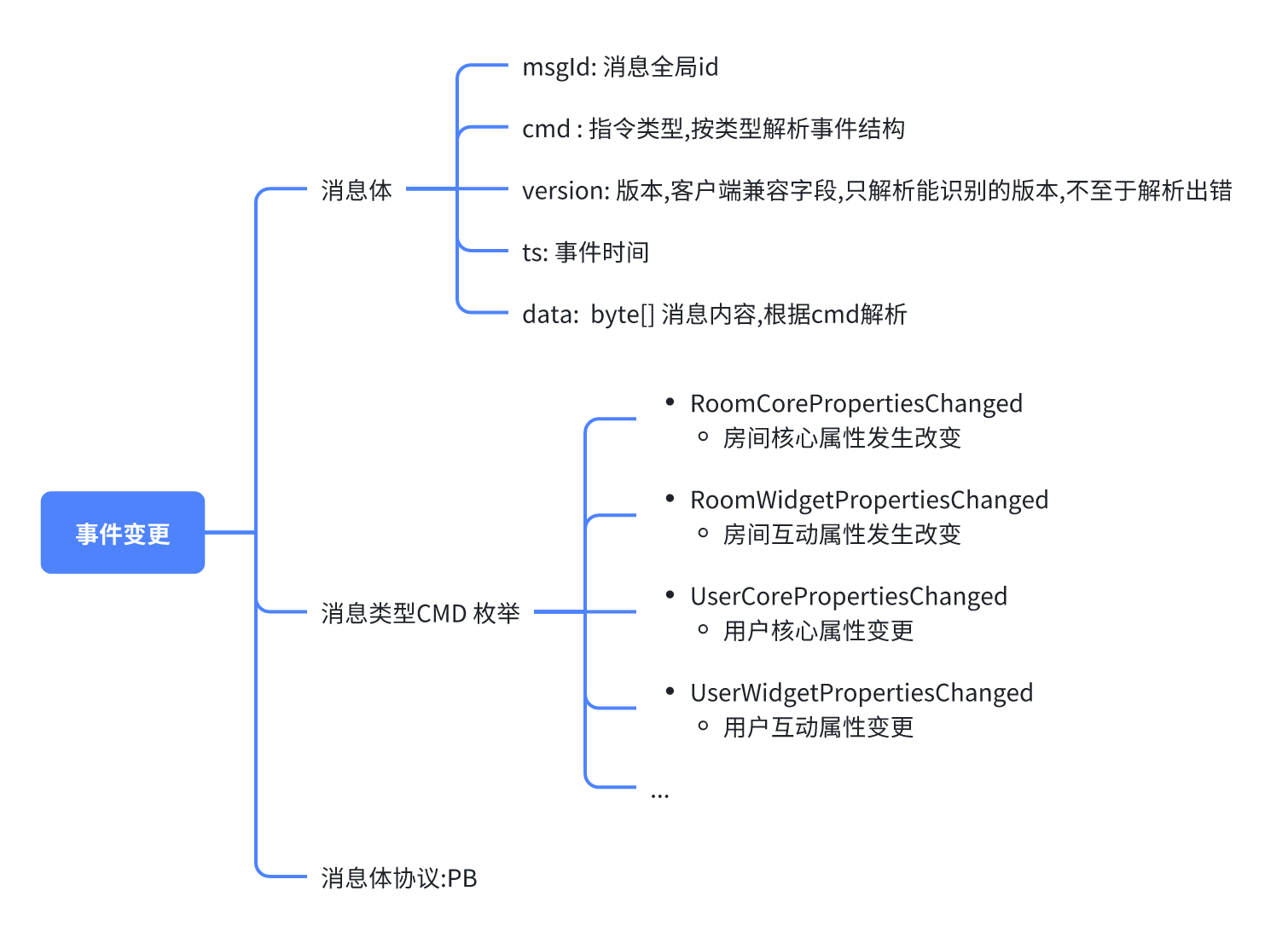
事件结构
实践过程中遇到的问题
-
grpc 长链接,在 K8s 环境中,1分钟会断链一次,需要在 ingress nginx 开启超时配置
12nginx.ingress.kubernetes.io/backend-protocol: GRPC #声明使用grpc服务nginx.ingress.kubernetes.io/server-snippet: grpc_read_timeout 3h;grpc_send_timeout 3h; -
压测时,channel 到 h3proxy 的消息大批量丢失,原因是 streamObserver 非线程安全。导致发送的消息错乱,h3proxy 读取失败会报 failed to unmarshal the received message proto: cannot parse invalid wire-format data,streamObserver 使用时需要加锁串行
-
channel grpc stream 双向流,转发数据时直接左手倒右手,上下游的发送速率会互相影响,导致吞吐性能不高,需要先进发送队列,再送出去,屏蔽两端的速度差
-
长时间运行后 channel 线程泄漏
121. 从 queue 中读取消息应该用 poll,不能用take,不然当没有消息时,没有时机实现中断逻辑2. 中断线程方法不能用 interrupt 或者 stop,而是自己设置标志位
-
h3proxy 性能上不去,CPU 异常高,pprof 发现是协程泄漏,原因是第三方消费队列实现有问题,某一些客户端慢连接,送不出去消息时会阻塞住,需替换为无锁队列
-
h3proxy 和 channel 上下行包体过大时,吞吐性能上不去,解决方案:预热连接池,上行时根据路由分组,用多个连接发送数据
-
压测时 nginx 网关带宽过高,高负载影响吞吐,方案:不同模块隔离网关,条件允许时直连,去除不必要中间组件
-
h3proxy 全局锁优化,链接资源提前初始化,用户登录逻辑异步化
如何解决的
-
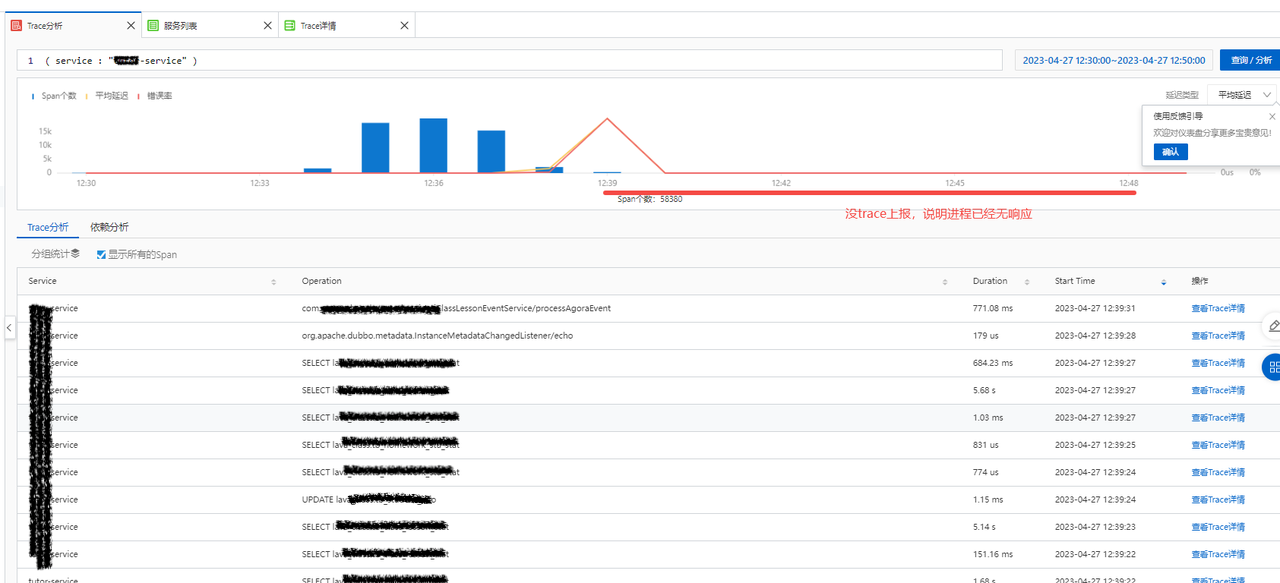
消息投递链路埋点,分析消息数量和时延,快速诊断问题点在哪个环节
-
压测平台建设,业务数据模拟,客户端加压,流量复制,通过压测暴露高并发情况下的架构问题和细节问题
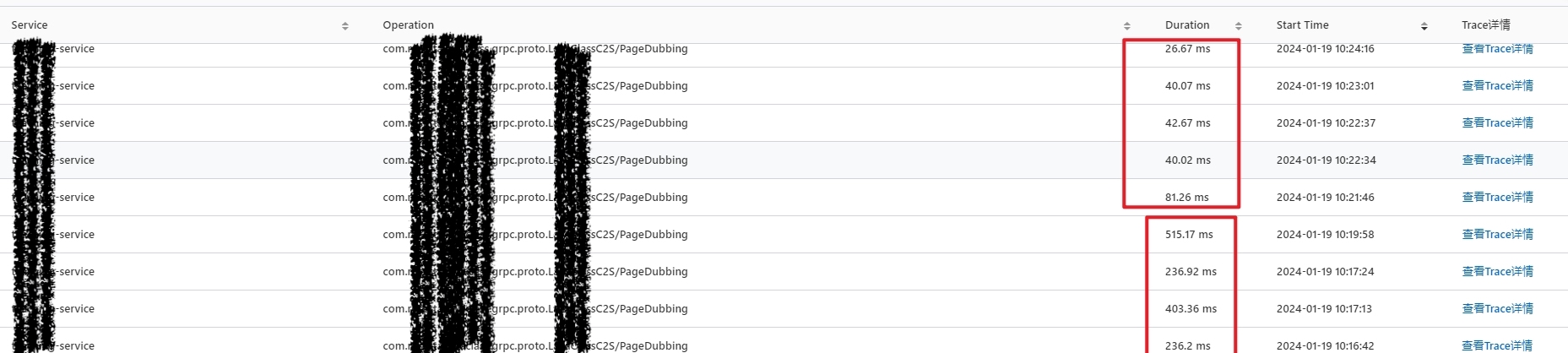
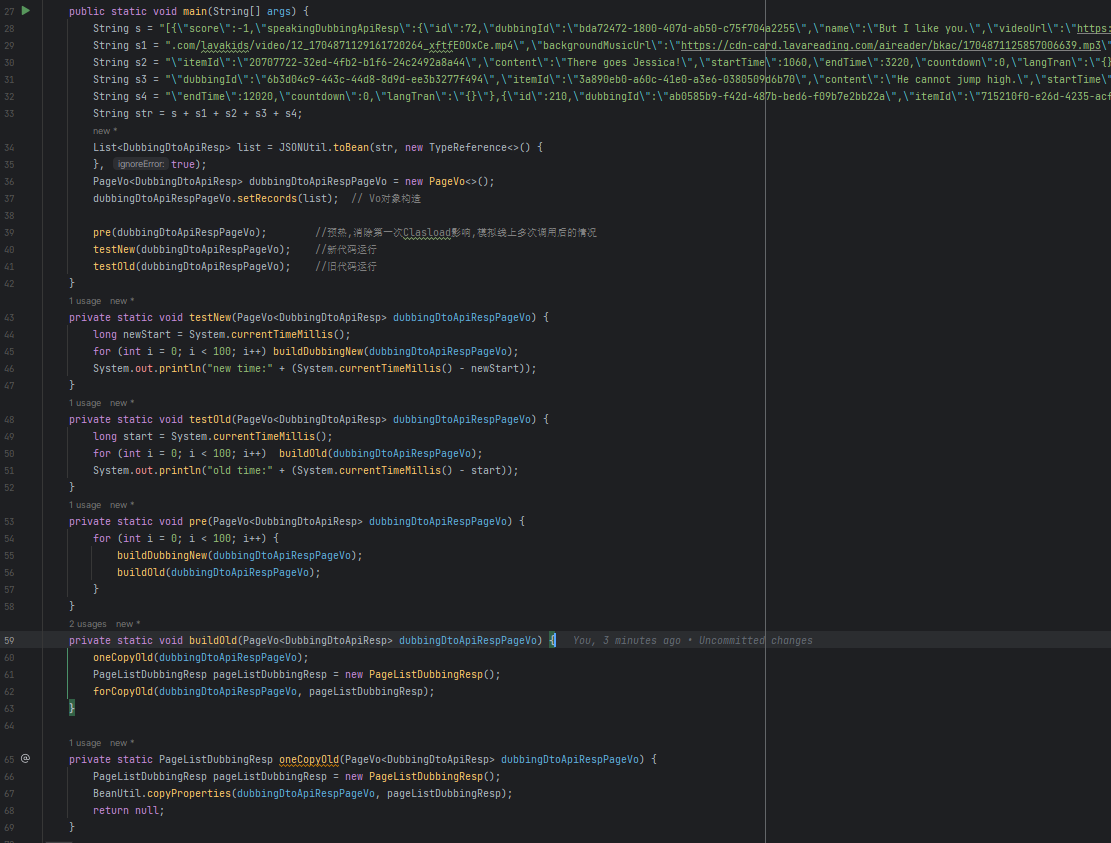
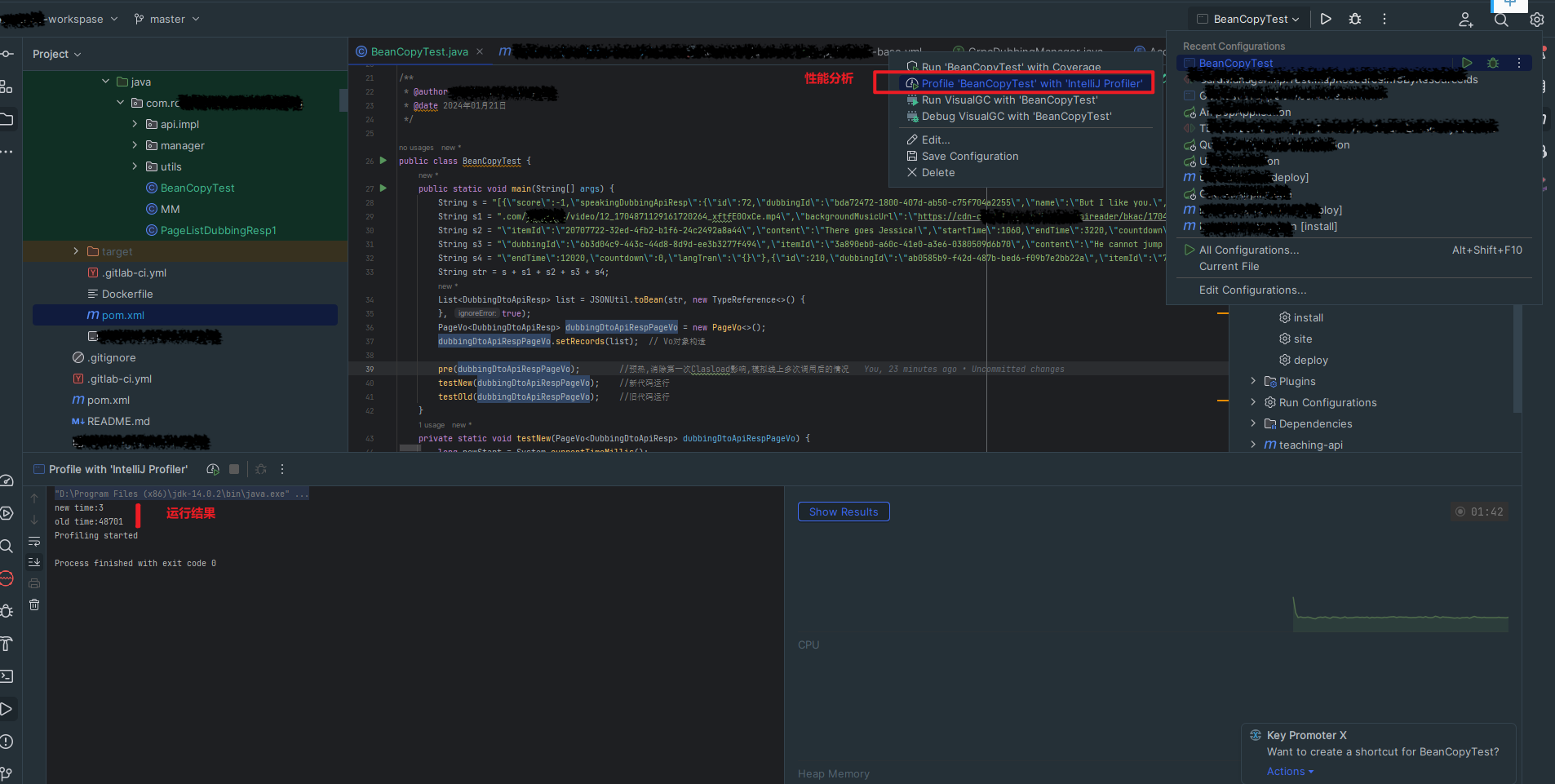
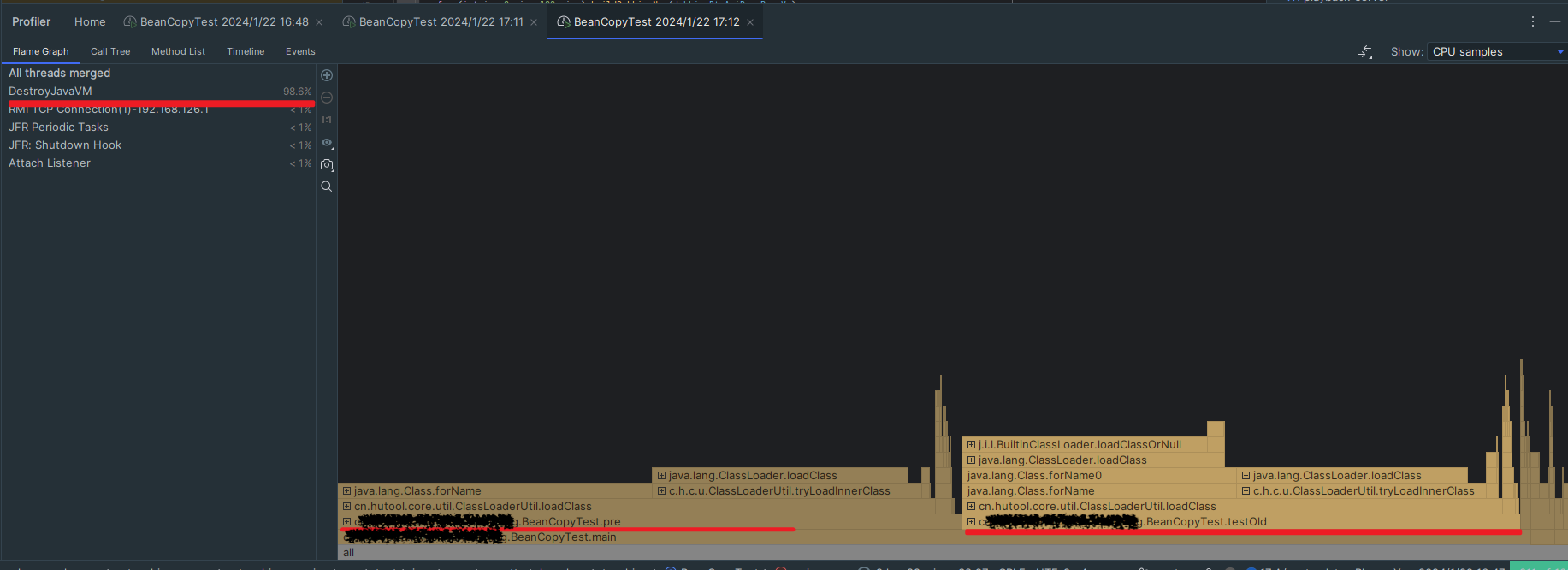
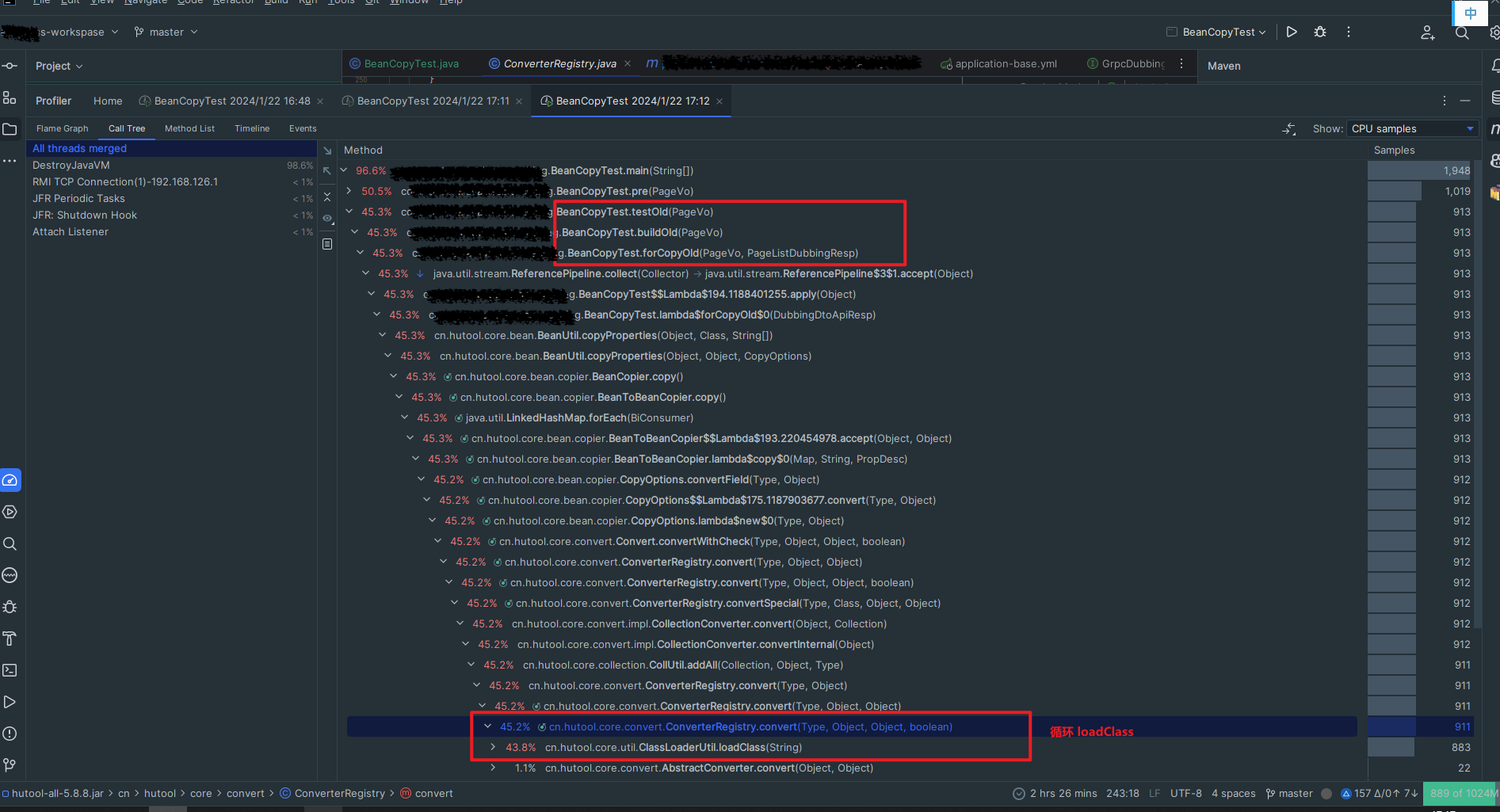
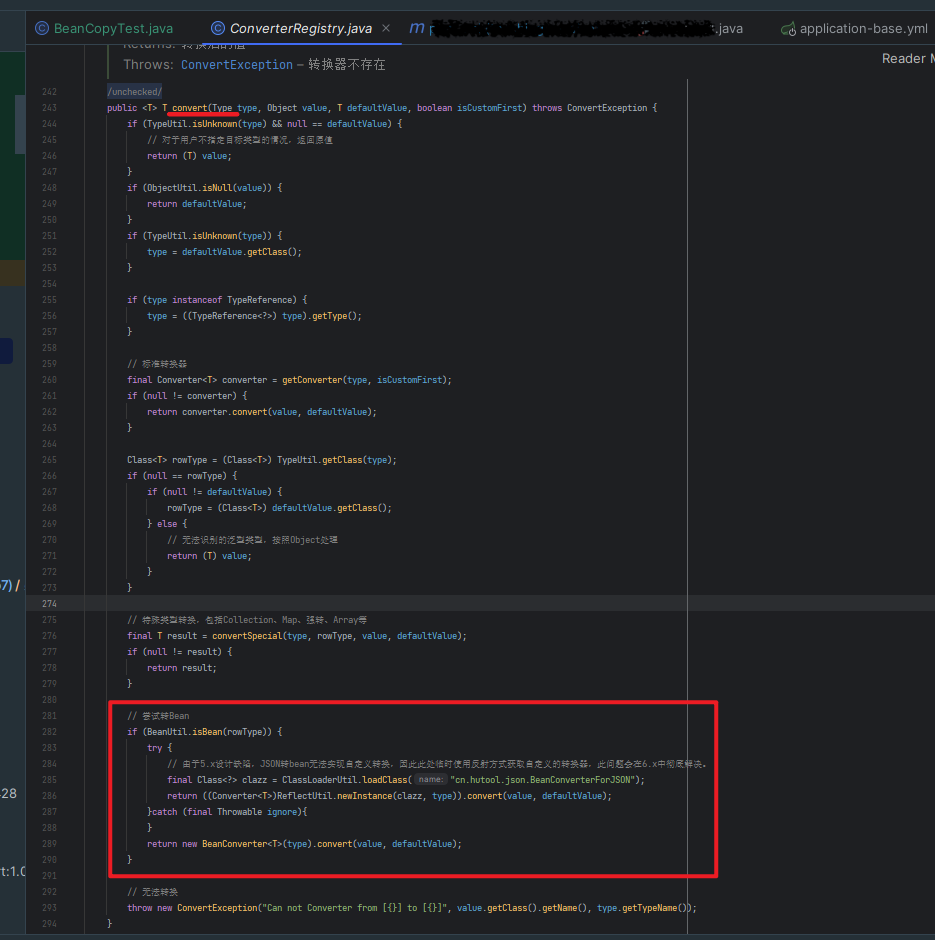
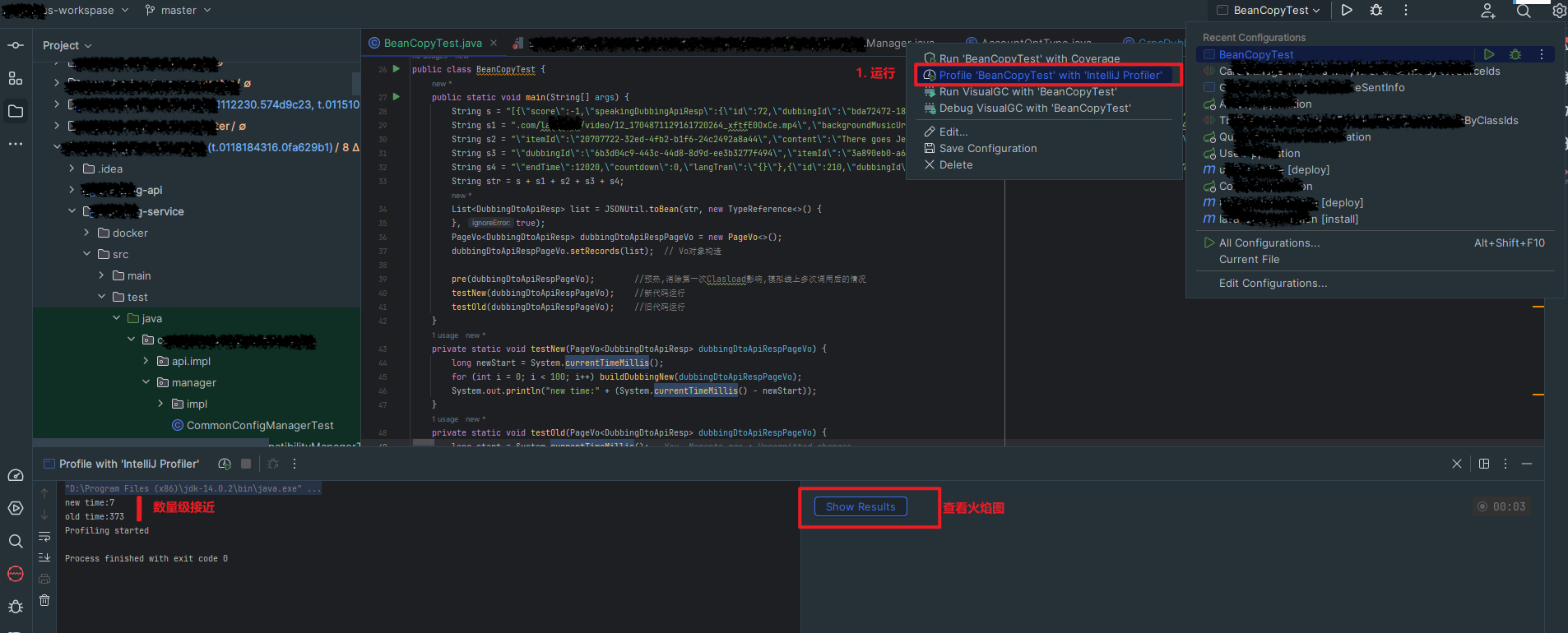

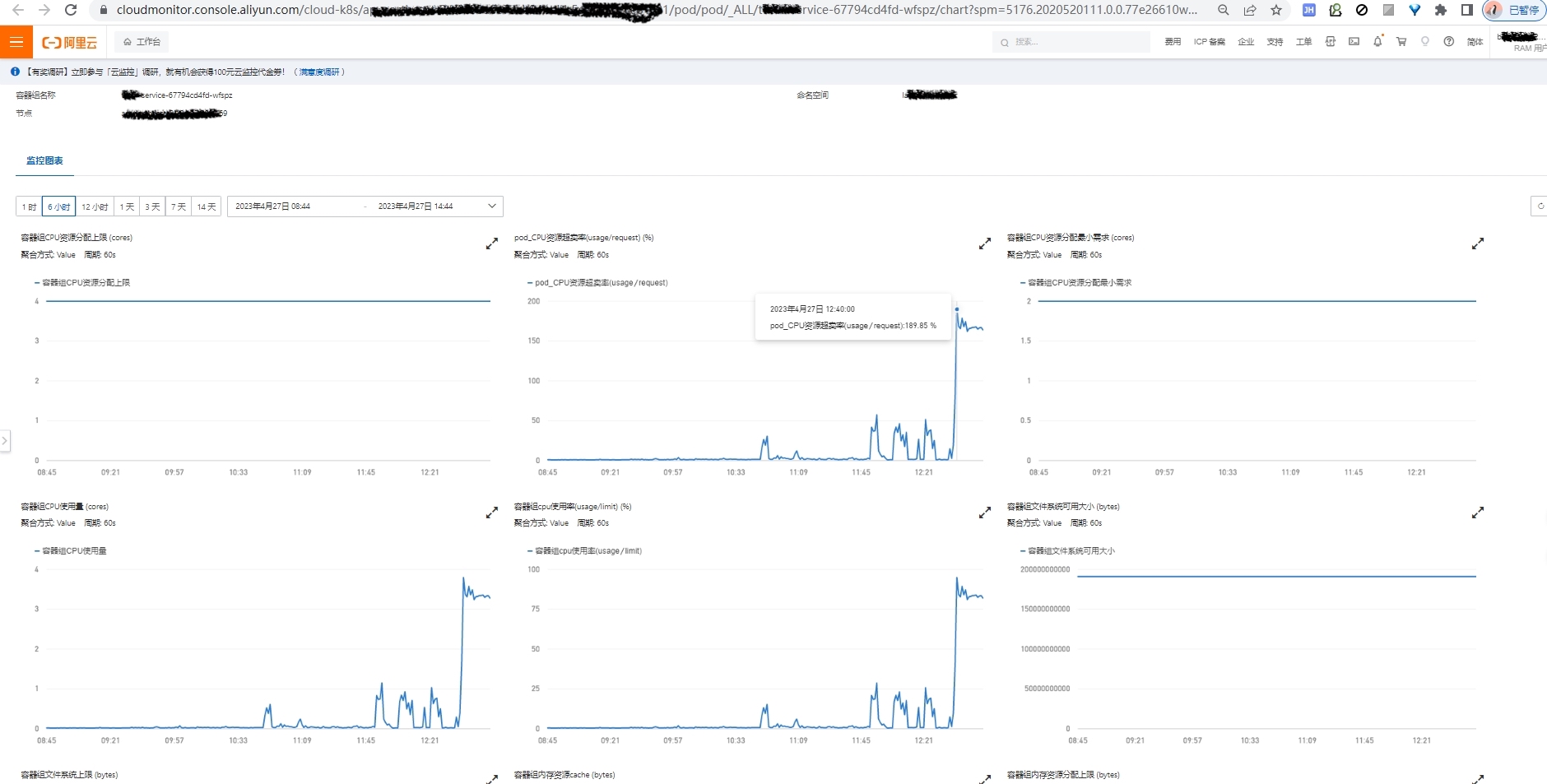
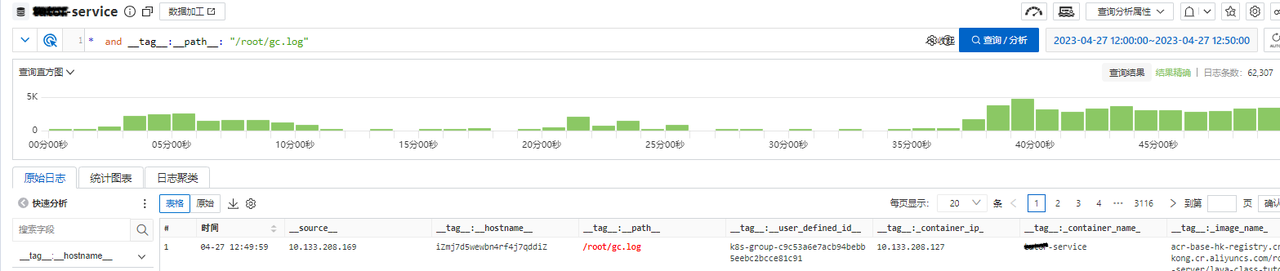
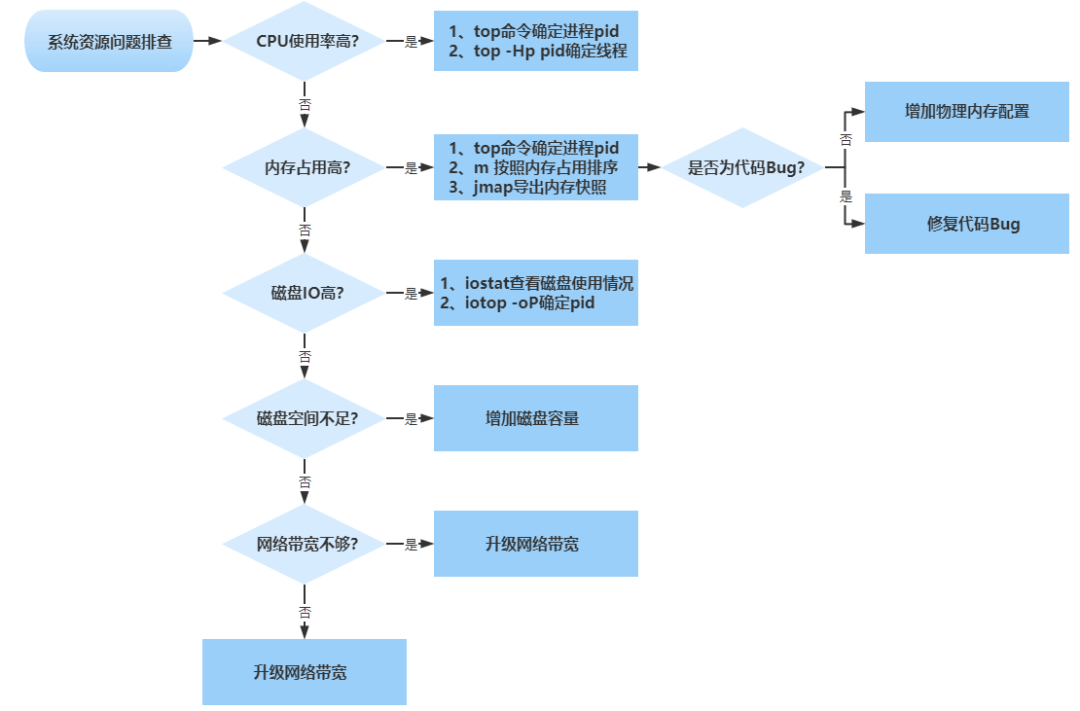
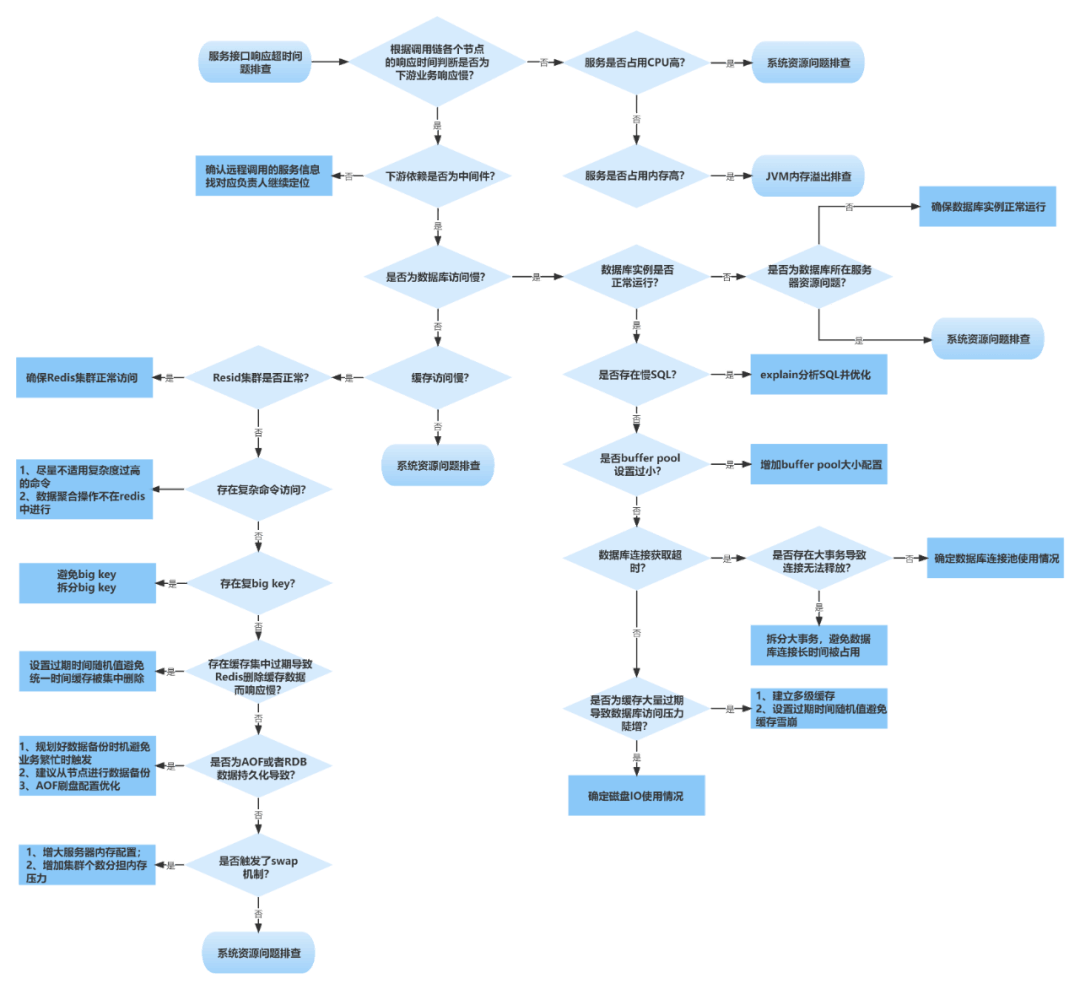
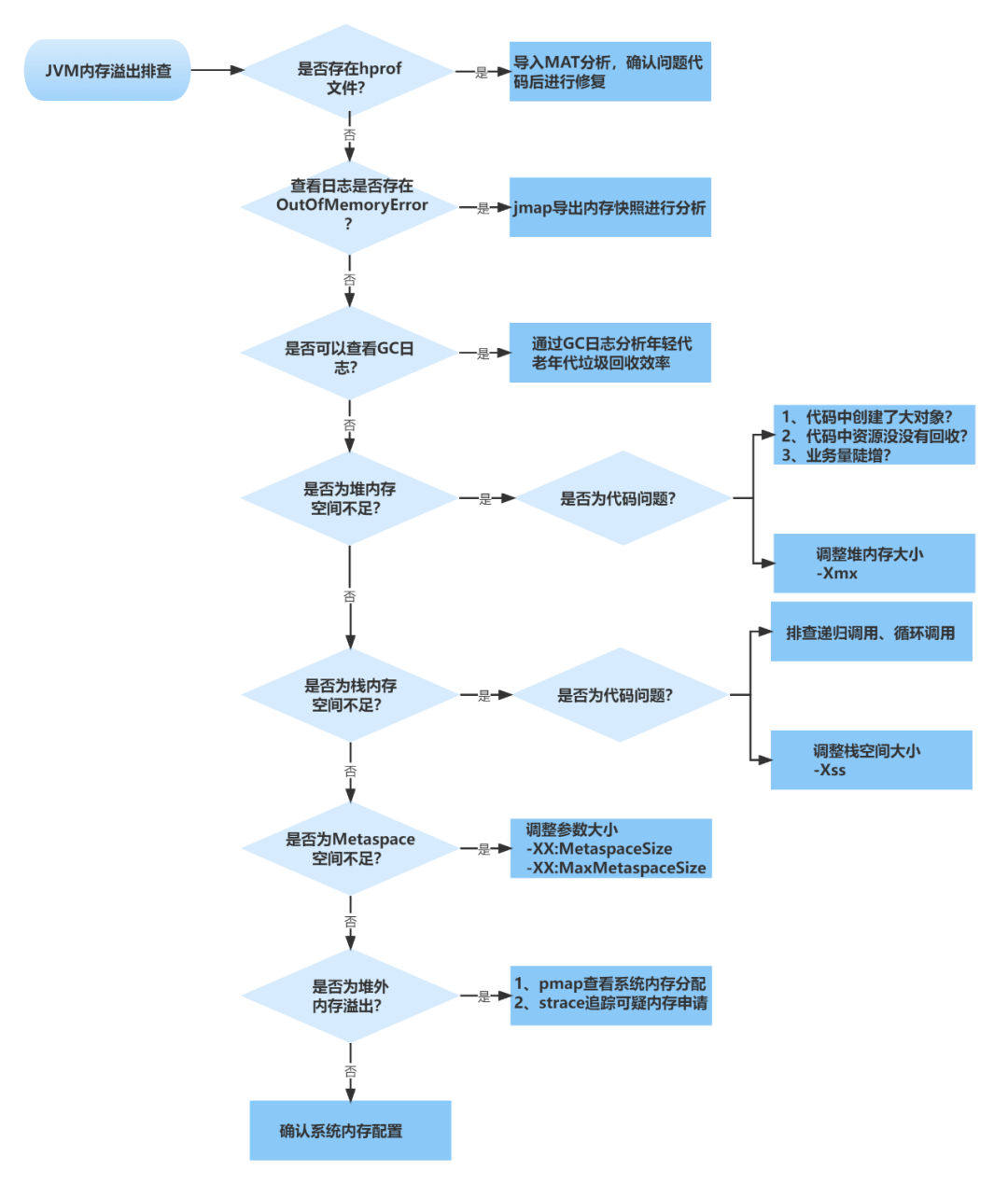
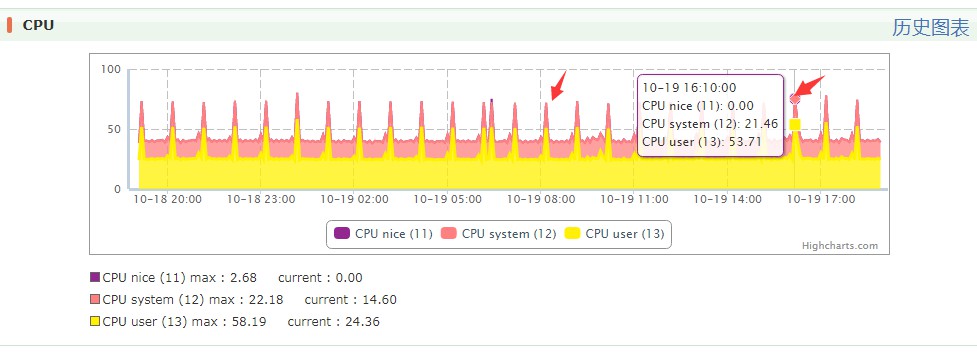
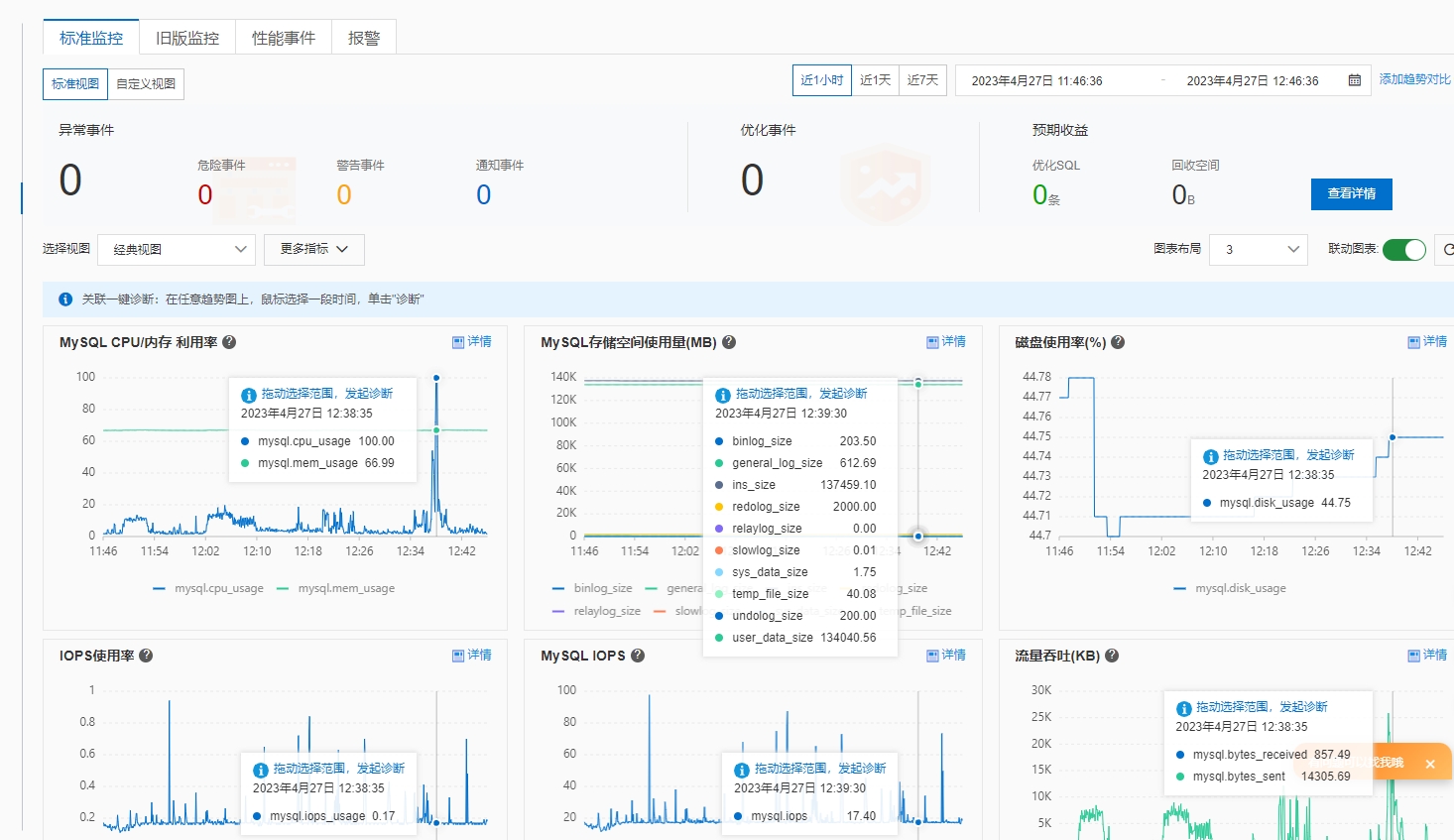 细看数据库引擎情况,分析 CPU 100% 原因,发现没有慢 SQL 等其他异常, 更新和扫描行数也正常,通过 TPS 分析发现 SQL 执行次数飙升
细看数据库引擎情况,分析 CPU 100% 原因,发现没有慢 SQL 等其他异常, 更新和扫描行数也正常,通过 TPS 分析发现 SQL 执行次数飙升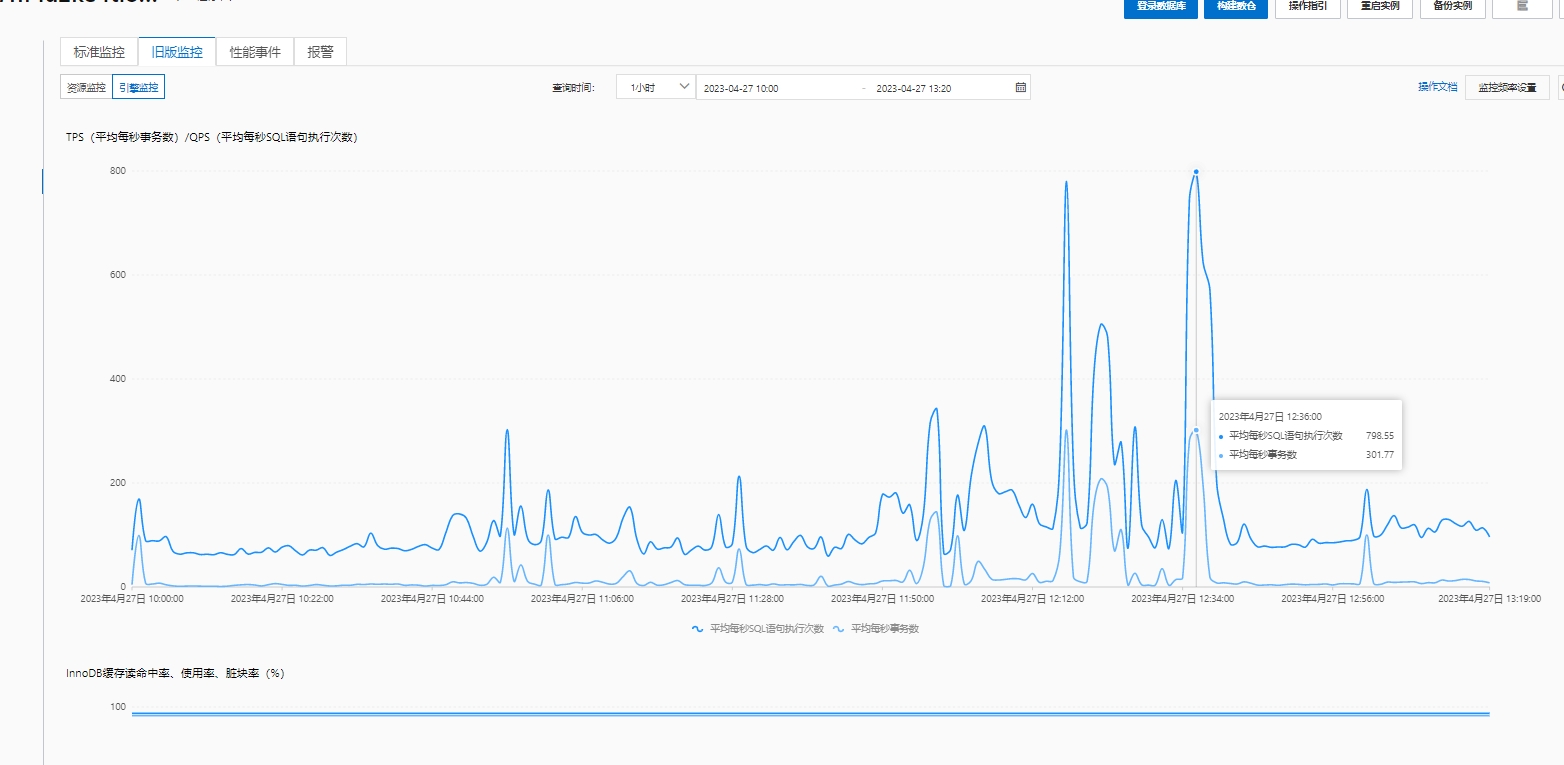

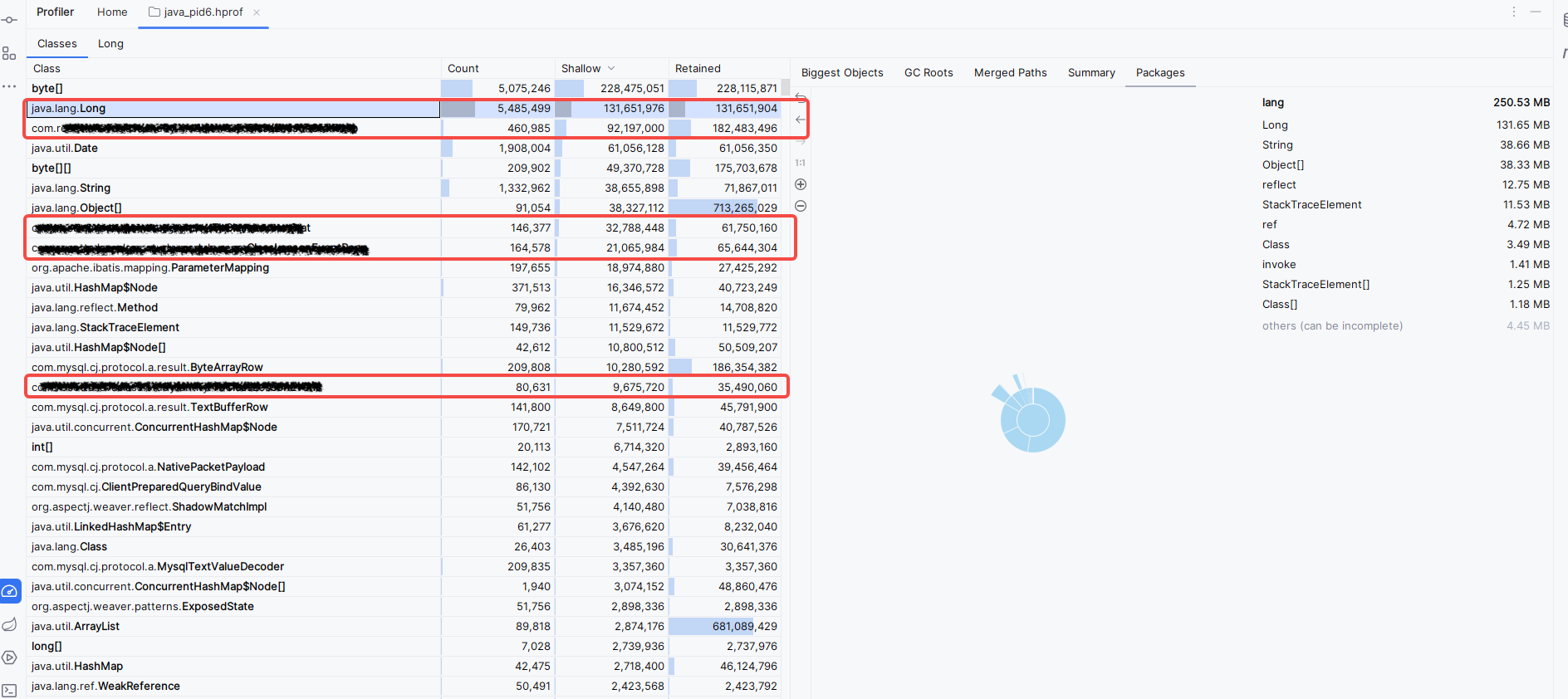


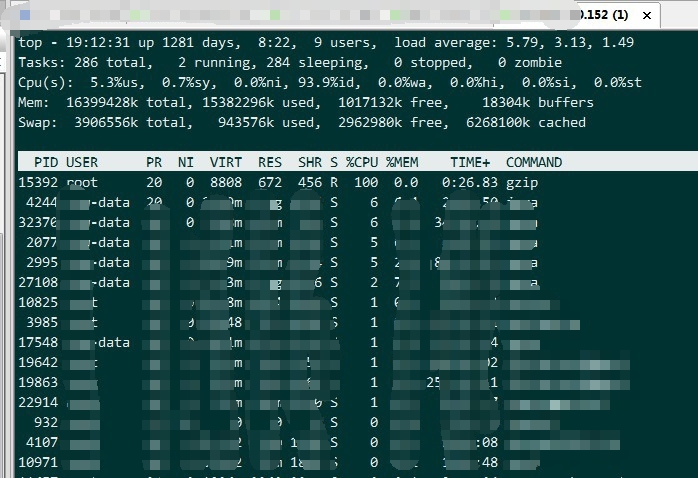 得知占用最大的程序为 gzip ,但是查不到 gzip 进行什么操作,无解
得知占用最大的程序为 gzip ,但是查不到 gzip 进行什么操作,无解
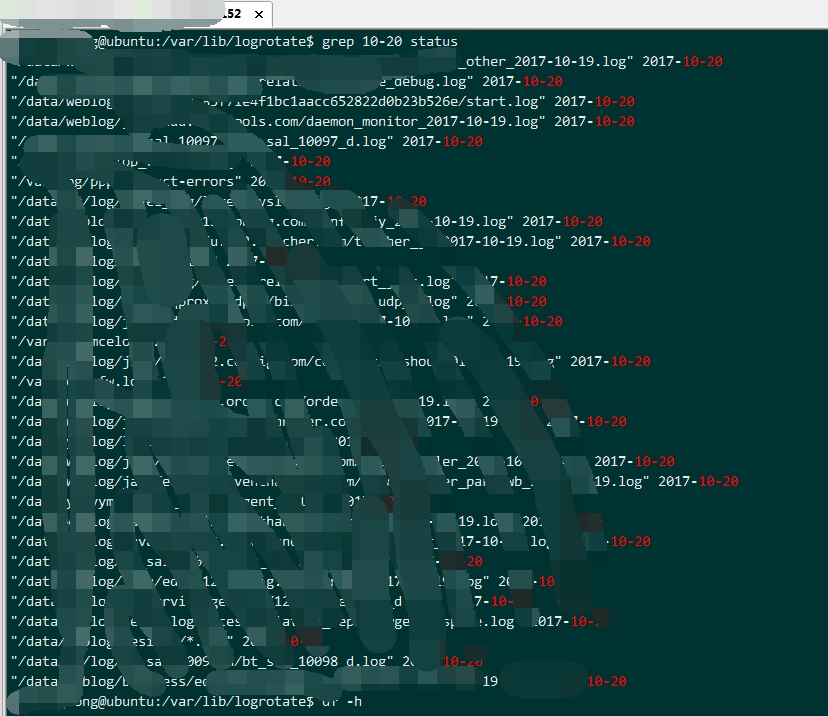 检查 logrotate 操作的文件大小
检查 logrotate 操作的文件大小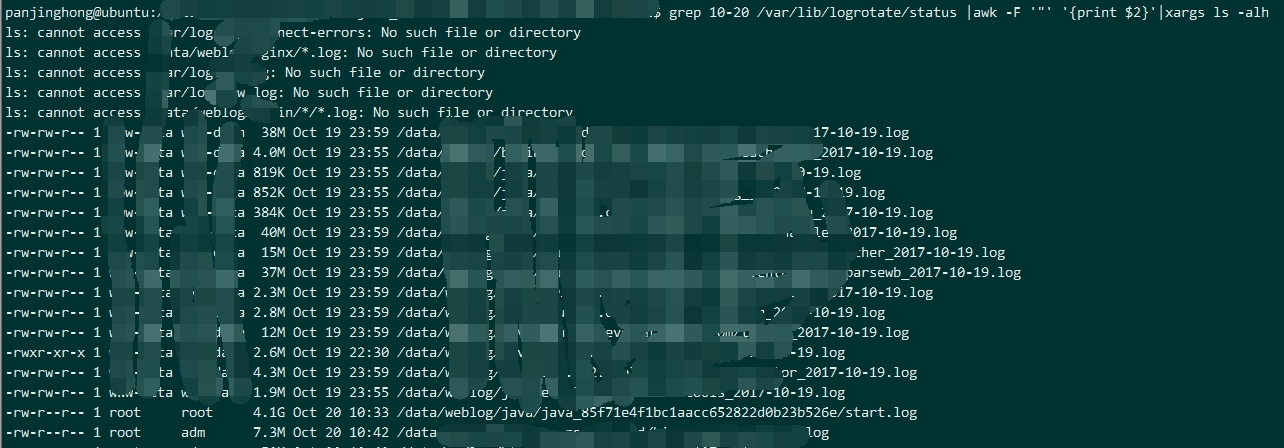 倒数第二行,发现文件大小异常,检查日志文件所属程序,发现是遗留的 kafka 程序
倒数第二行,发现文件大小异常,检查日志文件所属程序,发现是遗留的 kafka 程序
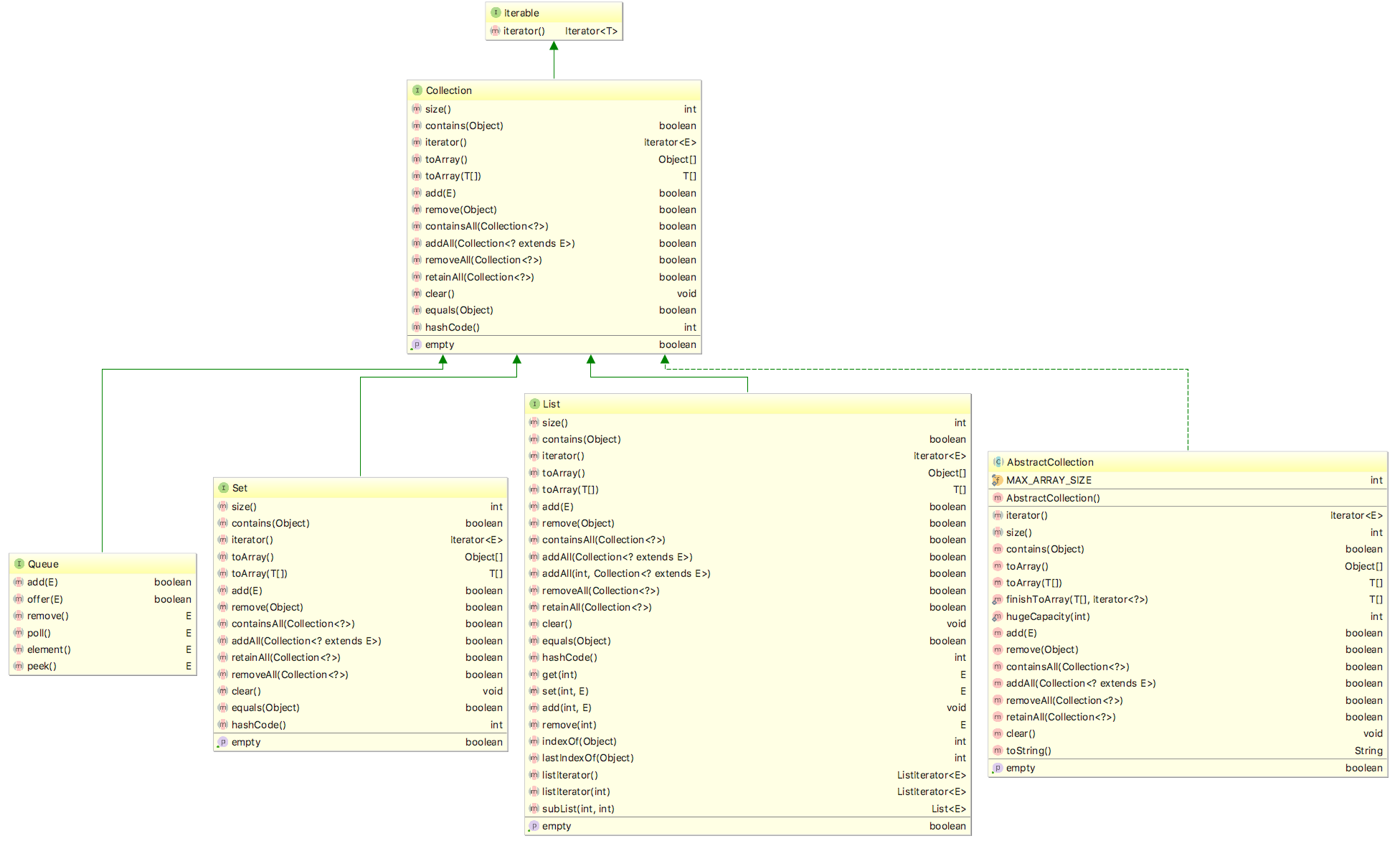



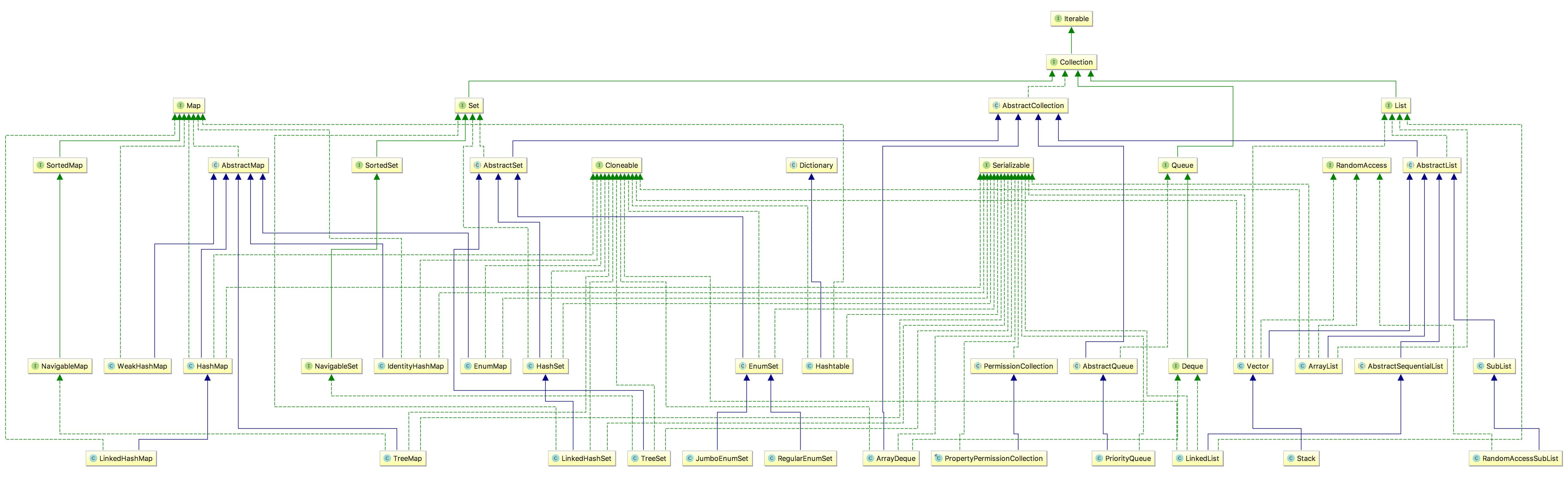
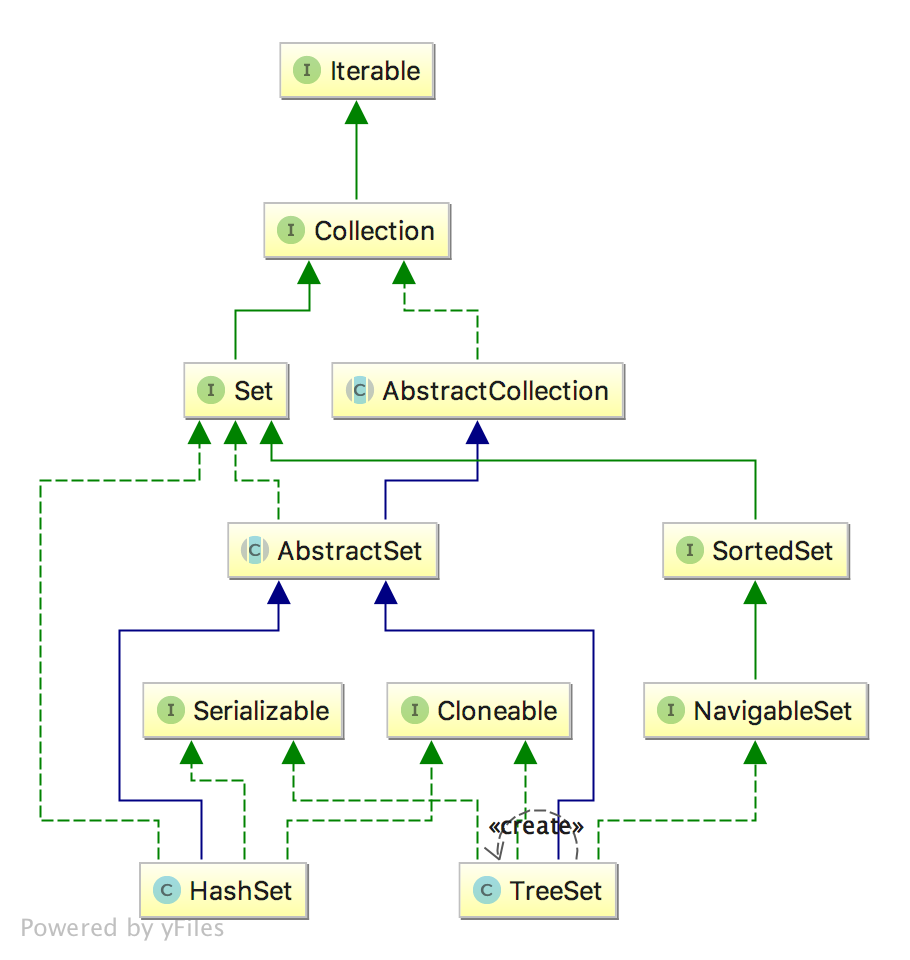 可以看到,TreeSet 和 HashSet 都继承了 AbstractSet,都实现了 Serializable、Cloneable 接口,但是对于 HashSet 来说,TreeSet 实现了 NavigableSet、SortedSet 接口
SortedSet 具有排序功能,它支持对 Set 中的元素排序,提供了三大功能,分别是
可以看到,TreeSet 和 HashSet 都继承了 AbstractSet,都实现了 Serializable、Cloneable 接口,但是对于 HashSet 来说,TreeSet 实现了 NavigableSet、SortedSet 接口
SortedSet 具有排序功能,它支持对 Set 中的元素排序,提供了三大功能,分别是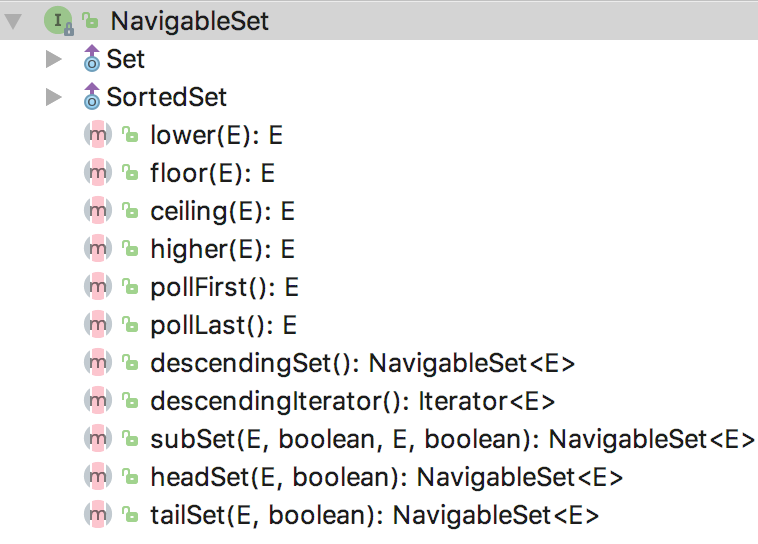

 由
由