
前言
在SRE领域,有两个指标
- MTBF,Mean Time Between Failure,平均故障时间间隔,MTBF系统正常运行的阶段
- MTTR,Mean Time To Repair, 故障平均修复时间,MTTR则意味着系统故障状态
MTTR 故障是不可避免的,我们指定运维制度的目标,目的是为了提高 MTBF时间,减低MTTR时间
MTTR又分四个指标
- MTTI平均故障发现时间,从故障实际发生,到我们真正开始响应时间
- MTTK平均故障认知时间,根因定位定位时间
- MTTF平均故障解决时间,根据根因,采取措施恢复业务为止
- MTTV平均故障修复验证时间,故障解决后,通过验证确认业务真正恢复所用时间
如何降低MTTI平均故障发现时间,我们通过值班制度保障
如何降低MTTK 平均故障认知时间,MTTF平均故障解决时间,我们通过学习查障手段来保障
值班人员职责及流程
职责:
-
发现问题
- 关注用户主动反馈群--------用户反馈问题
- 关注后端技术指标报表波动 -----请求量波动、错误率波动、时延波动
- 关注后端日志错误告警群 ------关注程序运行中意想不到的分支
- 关注服务组件状态 ----- 线程状态、进程状态、机器负载、CPU、内存、文件IO、网络、数据库负载
- 关注业务状态 ----- 注册人数、登录人数、订单数量、账本变动数
-
甄别问题优先级
-
在值班记录表(飞书表格)中记录值班期间发生的问题,跟进推进问题解决
-
紧急问题、非紧急2小时没有找到原因的问题,上报上级,做出预警
-
组内站会时,介绍出现问题的调查过程及问题原因,加强监控措施并优化处理时长
流程:
-
值班人按天进行排班,时间为周一到周日,早上9:30-23:00,周任务安排时,会预留余量,用于处理值班事务
-
根据值班表,值班人当天,在飞书接收各告警群的问题反馈,并且检查线上服务组件状态
- 业务反馈群
- 技术告警群
-
当收到告警、报障,在飞书上创建问题,生成问题单,跟踪问题进展
-
定位并解决问题、及时反馈业务,对于无法单独处理的问题要及时上报
-
问题解决完成后,在飞书上记录问题单信息,标记解决
常用查障手段
了解系统对外提供了什么
- 系统承载了哪些业务? 业务A/业务B
- 系统由哪些模块组成? 订单/注册
- 系统以什么方式对外提供服务?用户设备直接请求?业务后台转发?HTTP 接口?gRPC 接口?MQ?
了解系统部署架构
- 系统有多少个进程组成?各个进程的职能是什么
- 系统部署的IDC、K8s集群、云日志位置、Trace日志的位置
- 系统对外暴露的 Service、路由、域名
了解系统依赖了什么
-
系统依赖的存储组件有哪一些?以及使用方式和重要级别?
- 数据库?数据存储类型?日志?配置?业务数据?
- Redis?作用?分布式锁?业务逻辑依赖?缓存?
- 消息队列?生产者和发送时机、消费者和消费逻辑、Topic的重要级别和消息量
- 注册中心、配置中心?
-
系统依赖的第三方组件
- 第三方组件的功能,重要级别,调用方式,调用频率,重试机制
了解系统什么情况是正常的
- 从业务流程验证,如每天会下一笔单验证下单流程没问题
- 业务数据维度验证,下单量、注册量
- 接口请求情况验证,请求量、时延、成功率
- 日志维度,查看请求日志正常
了解目前系统的问题范围
- 全系统故障
- 模块故障
- 偶发故障
- 某个用户故障
问题定位
-
全系统故障
-
最严重故障,需要全员介入,各个维度排查
-
确定是客户端故障,还是服务端故障?
-
域名解析问题?dns故障?证书问题?
-
网络故障?客户端网络故障?服务端机房网络故障?
-
接入层故障?接入ip可达性?接入层Ingress故障?运营商流量黑名单?
-
后端服务部署故障?服务进程崩溃?服务进程负载过高?
-
服务内部逻辑错误?配置错误?数据库连接故障?线程池故障?业务数据错误?
-
内部依赖故障?数据库故障?redis故障
-
第三方依赖故障?
-
后端进程所在机器故障?磁盘?CPU?内存?网络
-
-
模块故障/偶发故障
-
一般是模块内部错误,可先快速查看模块日志,尝试快速定位
-
如果未能快速定位,则需要寻找规律,按全网故障的排查手段,比较没故障和故障的组件之间的差异,网络不同?数据库不同等,偶发故障需要寻找规律,看出是时间规律还是请求量规律
-
-
某个用户故障
- 一般情况下是用户数据异常,导致触发异常分支
止损
止损前提是明确了影响范围和故障模块,已经定位出了故障原因,已经有稳妥的修复方案,并且经过讨论Review,排除掉风险点,考虑了修复,回滚范围后才进行操作,避免以下操作:
改进
-
健壮性原则:例如,在 B 依赖 A 的状态下,被依赖方 A 出现问题,但是能够快速恢复,而依赖方 B无法快速恢复,导致故障蔓延。这时,承担主要责任的是依赖方 B,而不是被依赖方 A
-
第三方默认无责:这一条是上一条的延伸,如果使用到了第三方的服务,如公有云的各类服务,包括 IaaS、PaaS、CDN 以及视频等等,我们的原则就是默认第三方无责
监控:确保发布质量的监控项
-
核心质量数据
-
日志(确保功能跑到并正常)
-
监控机器人
排查定位大图
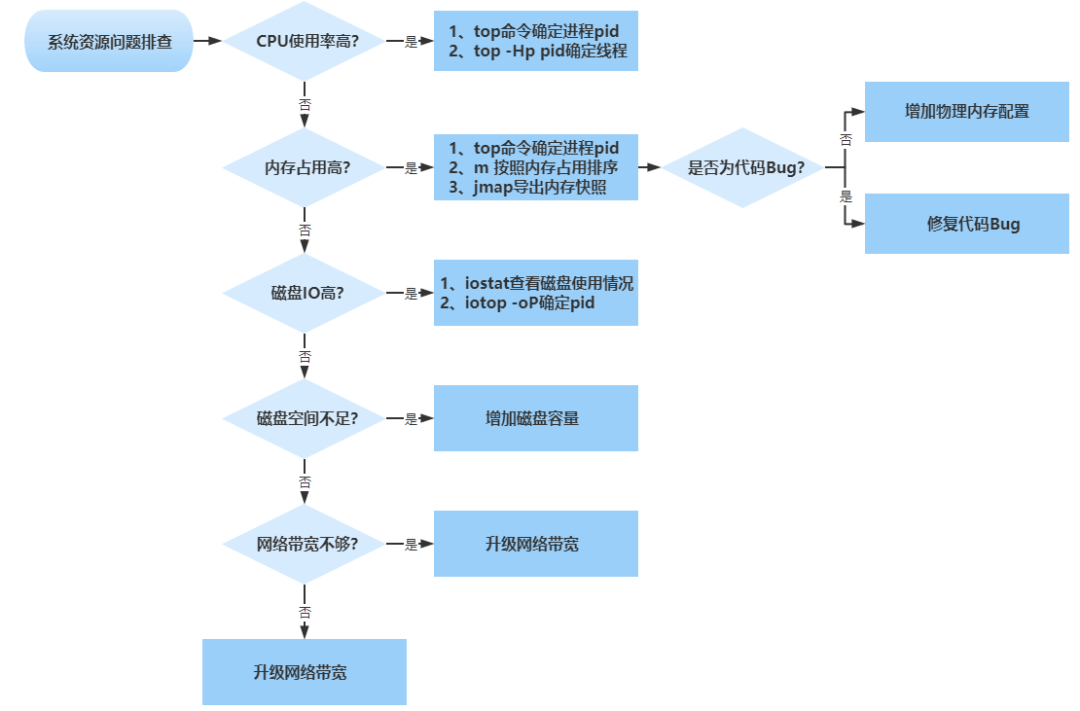
系统资源问题定位
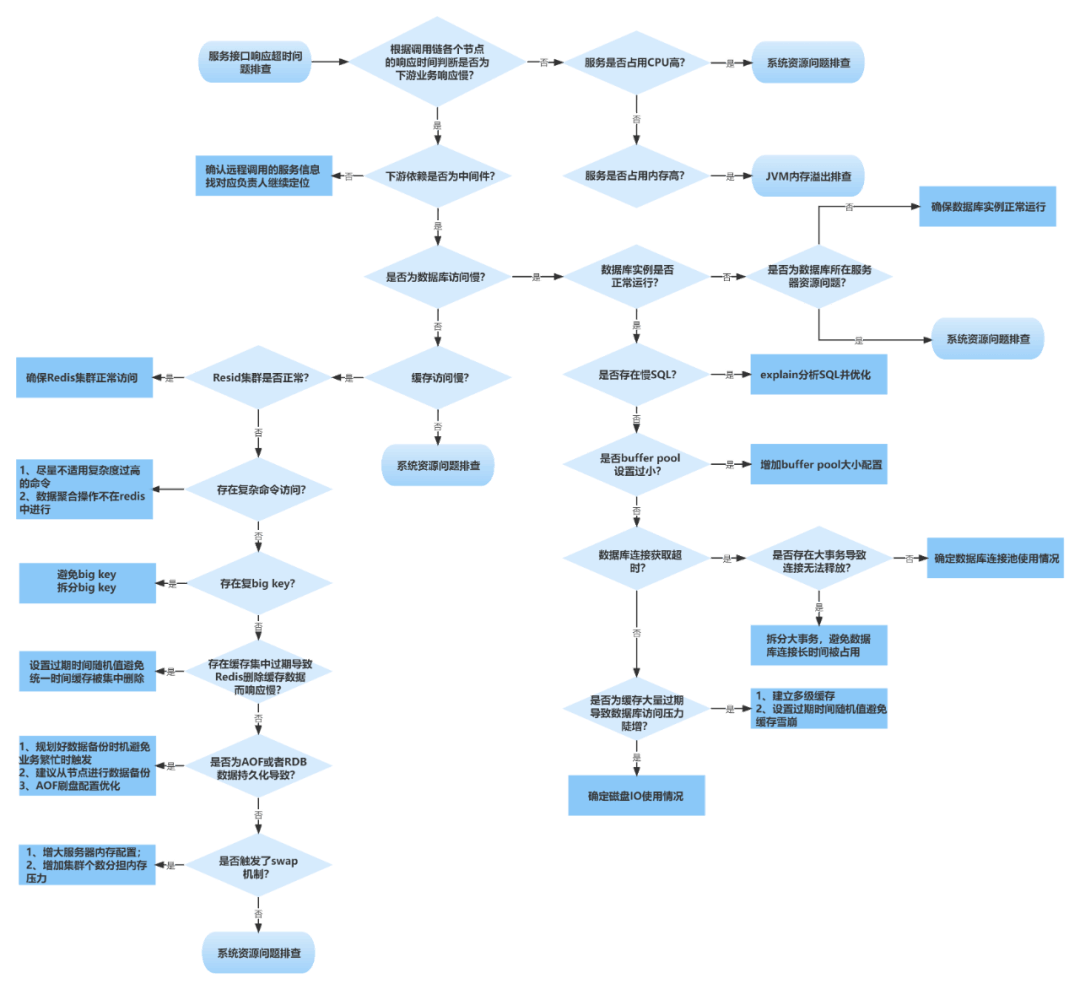
接口响应慢问题定位
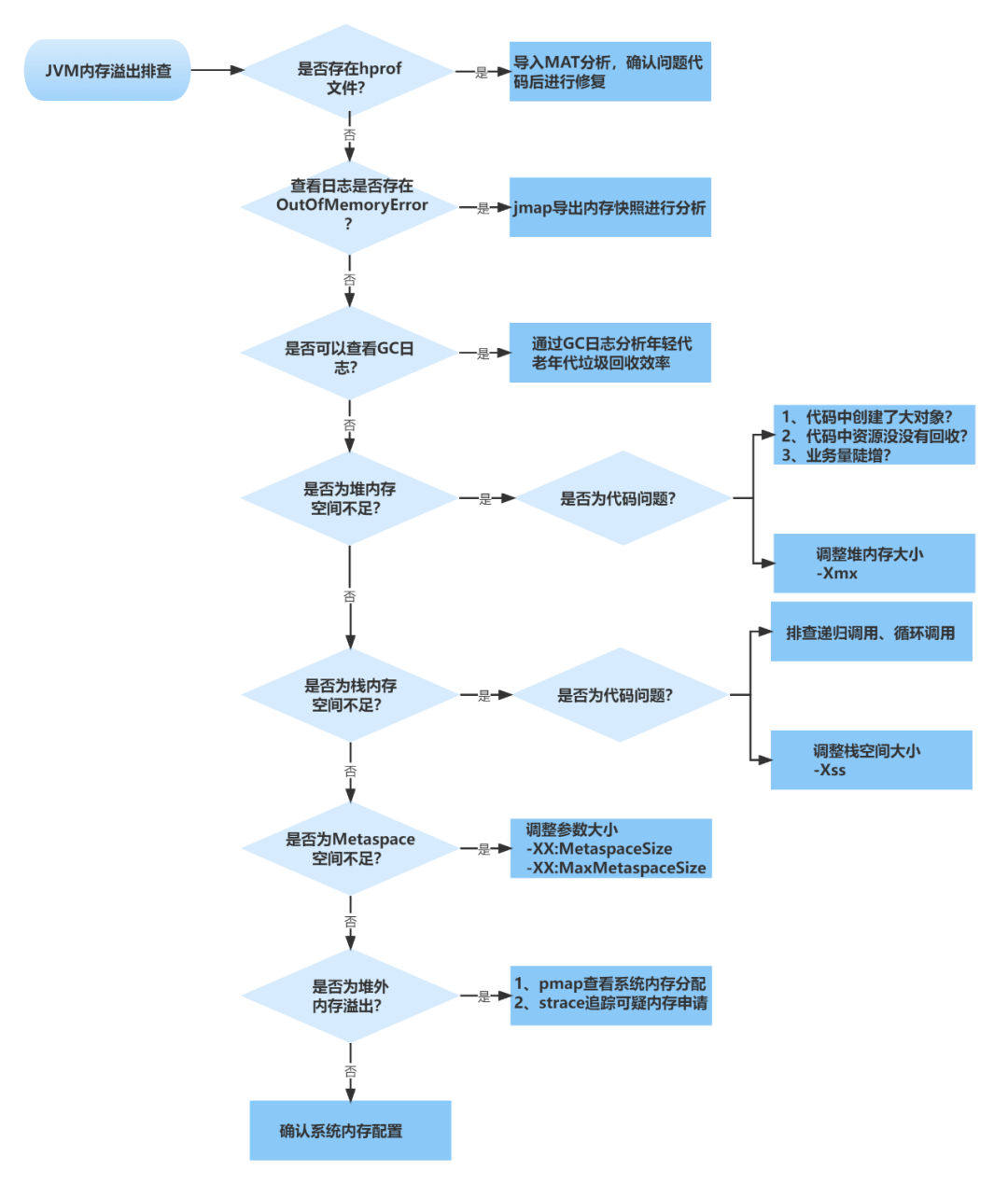
JVM内存溢出问题定位
03 | SRE切入点:选择SLI,设定SLO_Yule的技术博客_51CTO博客
https://sre.google/workbook/how-sre-relates/